出处: https://ocw.mit.edu/courses/6-050j-information-and-entropy-spring-2008/pages/bits-codes/翻译: ChatGPT
Codes
在前一章中,我们探讨了信息的基本单位,即比特,以及它的各种抽象表示形式:布尔比特(及其相关的布尔代数和在组合逻辑电路中的实现)、控制比特、量子比特和经典比特。
In the previous chapter we examined the fundamental unit of information, the bit, and its various abstract representations: the Boolean bit (with its associated Boolean algebra and realization in combinational logic circuits), the control bit, the quantum bit, and the classical bit.
如果一个问题有且只有两个可能的答案,那么单个比特就很有用。例子包括掷硬币的结果(正面或反面)、一个人的性别(男性或女性)、陪审团的裁决(有罪或无罪)、以及一个断言的真伪(真或假)。大多数情况下,生活中的情况要复杂得多。本章涉及如何用比特数组而不是单个比特来表示复杂的对象。
A single bit is useful if exactly two answers to a question are possible. Examples include the result of a coin toss (heads or tails), the gender of a person (male or female), the verdict of a jury (guilty or not guilty), and the truth of an assertion (true or false). Most situations in life are more complicated. This chapter concerns ways in which complex objects can be represented not by a single bit, but by arrays of bits.
我们集中在一个非常简单的系统模型上,如图2.1所示,其中输入是预定的一组对象或“符号”中的一个,所选择特定符号的身份被编码成一个比特数组,这些比特通过空间或时间传输,然后在稍后的时间或不同的地点解码,以确定最初选择的是哪个符号。在后面的章节中,我们将扩展这个模型,以处理鲁棒性和效率问题。
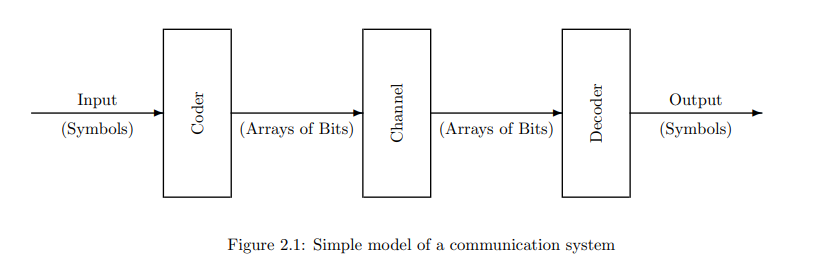
It is convenient to focus on a very simple model of a system, shown in Figure 2.1, in which the input is one of a predetermined set of objects, or "symbols," the identity of the particular symbol chosen is encoded in an array of bits, these bits are transmitted through space or time, and then are decoded at a later time or in a different place to determine which symbol was originally chosen. In later chapters we will augment this model to deal with issues of robustness and efficiency.
在本章中,我们将探讨代码设计的几个方面,并展示一些这些方面被做好或做得不好的例子。各个部分将描述一些代码,以说明重要的点。需要编码的对象包括:
字母:BCD、EBCDIC、ASCII、Unicode、摩尔斯电码
整数:二进制码、格雷码、二's补码
数字:浮点数
蛋白质:遗传密码
电话:NANP、国际代码
主机:以太网、IP地址、域名
图像:TIFF、GIF和JPEG
音频:MP3
视频:MPEG
In this chapter we will look into several aspects of the design of codes, and show some examples in which these aspects were either done well or not so well. Individual sections will describe codes that illustrate the important points. Some objects for which codes may be needed include:
Letters: BCD, EBCDIC, ASCII, Unicode, Morse Code
Integers: Binary, Gray, 2's complement
Numbers: Floating-Point
Proteins: Genetic Code
Telephones: NANP, International codes
Hosts: Ethernet, IP Addresses, Domain names
Images: TIFF, GIF, and JPEG
Audio: MP3
Video: MPEG
2.1 符号空间大小
首先要解决的问题是需要编码的符号数量。这被称为符号空间大小。我们将考虑不同大小的符号空间:
1
2
整数次幂的2
有限
无限,可数
无限,不可数
The first question to address is the number of symbols that need to be encoded. This is called the symbol space size. We will consider symbol spaces of different sizes:
1
2
Integral power of 2
Finite
Infinite, Countable
Infinite, Uncountable
如果符号的数量是$$,那么选择可以用一个比特编码。如果可能的符号数量是$$、$$、$$、$$、$$或其他整数次幂的2,那么选择可以用等于符号空间大小以2为底的对数的比特数来编码。
If the number of symbols is 2, then the selection can be encoded in a single bit. If the number of possible symbols is 4, 8, 16, 32, 64, or another integral power of 2, then the selection may be coded in the number of bits equal to the logarithm, base 2, of the symbol space size.
因此,$$个比特可以指定一张扑克牌的花色(梅花、方块、红心或黑桃),而$$个比特可以编码一个班级中$$个学生中的一个选择。作为一个特例,如果只有一个符号,则不需要任何比特来指定它。陀螺是一种四面玩具,上面刻有希伯来字母,像陀螺一样在儿童游戏中旋转,特别是在光明节时。每次旋转的结果可以用$$个比特编码。
Thus 2 bits can designate the suit (clubs, diamonds, hearts, or spades) of a playing card, and 5 bits can encode the selection of one student in a class of 32. As a special case, if there is only one symbol, no bits are required to specify it. A dreidel is a four-sided toy marked with Hebrew letters, and spun like a top in a children's game, especially at Hanukkah. The result of each spin could be encoded in 2 bits.
如果符号数量是有限的但不是整数次幂的2,那么可以使用适用于下一个更高整数次幂的2的比特数来编码选择,但会有一些未使用的比特模式。
If the number of symbols is finite but not an integral power of 2, then the number of bits that would work for the next higher integral power of 2 can be used to encode the selection, but there will be some unused bit patterns.
例子包括10个数字、立方骰子的六个面、扑克牌的13个面值以及英语字母表的26个字母。在每种情况下,都有备用容量(4位表示数字时有6个未使用模式,3位表示骰子时有2个未使用模式,等等)。如何处理这种备用容量是一个重要的设计问题,我们将在下一节讨论。
Examples include the 10 digits, the six faces of a cubic die, the 13 denominations of a playing card, and the 26 letters of the English alphabet. In each case, there is spare capacity (6 unused patterns in the 4-bit representation of digits, 2 unused patterns in the 3-bit representation of a die, etc.) What to do with this spare capacity is an important design issue that will be discussed in the next section.
如果符号数量是无限但可数的(能够与整数进行一一对应),那么给定长度的比特串只能表示这个无限集合中的有限数量的项。
If the number of symbols is infinite but countable (able to be put into a one-to-one relation with the integers) then a bit string of a given length can only denote a finite number of items from this infinite set.
因此,非负整数的4位代码可能表示从0到15的整数,但无法处理超出此范围的整数。如果由于某些计算需要表示更大的数字,则必须以某种方式处理这种“溢出”情况。
Thus, a 4-bit code for non-negative integers might designate integers from 0 through 15, but would not be able to handle integers outside this range. If, as a result of some computation, it were necessary to represent larger numbers, then this "overflow" condition would have to be handled in some way.
如果符号数量是无限且不可数的(例如物理量如电压或声压的值),则必须使用某种“离散化”技术来用有限数量的选定值替换可能的值。
If the number of symbols is infinite and uncountable (such as the value of a physical quantity like voltage or acoustic pressure) then some technique of "discretization" must be used to replace possible values by a finite number of selected values that are approximately the same.
例如,如果符号是0到1之间的数字,并且有2个比特可用于编码表示,一种方法可能是将0到0.25之间的所有数字近似为0.125,将0.25到0.5之间的所有数字近似为0.375,依此类推。
For example, if the numbers between 0 and 1 were the symbols and if 2 bits were available for the coded representation, one approach might be to approximate all numbers between 0 and 0.25 by the number 0.125, all numbers between 0.25 and 0.5 by 0.375, and so on.
这种近似是否足够取决于解码数据的用途。这种近似是不可逆的,因为没有解码器可以仅根据近似值的代码恢复原始符号。然而,如果可用的比特数量足够多,那么对于许多用途,解码器可以提供一个足够接近的数字。
Whether such an approximation is adequate depends on how the decoded data is used. The approximation is not reversible, in that there is no decoder which will recover the original symbol given just the code for the approximate value. However, if the number of bits available is large enough, then for many purposes a decoder could provide a number that is close enough.
计算机中实数的浮点表示基于这种理念。
Floating-point representation of real numbers in computers is based on this philosophy.
2.2 剩余容量的使用
在许多情况下,由于符号的数量不是整数次幂的2,会有一些未使用的编码模式。处理这些情况有很多策略。以下是一些策略:
忽略
映射到其他值
预留以备将来扩展
用于控制代码
用于常见缩写
这些方法将通过常见编码的例子来说明。
In many situations there are some unused code patterns, because the number of symbols is not an integral power of 2. There are many strategies to deal with this. Here are some:
Ignore
Map to other values - Reserve for future expansion
Use for control codes - Use for common abbreviations
These approaches will be illustrated with examples of common codes.
2.2.1 二进制编码十进制 (BCD)
表示数字 0 - 9 的一种常见方法是通过表 2.1 中显示的十个四位模式。有六个比特模式(例如 1010)未被使用,问题是如何处理它们。这里有一些想法。
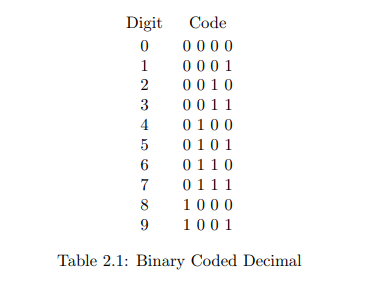
A common way to represent the digits 0 - 9 is by the ten four-bit patterns shown in Table 2.1. There are six bit patterns (for example 1010) that are not used, and the question is what to do with them. Here are a few ideas that come to mind.
首先,未使用的比特模式可以被简单地忽略。如果解码器遇到一个未使用的模式,可能是由于传输错误或编码错误,它可能返回空值,或者发出输出错误的信号。
First, the unused bit patterns might simply be ignored. If a decoder encounters one, perhaps as a result of an error in transmission or an error in encoding, it might return nothing, or might signal an output error.
其次,未使用的模式可以被映射到合法值。例如,所有未使用的模式都可以转换为 9,理论上它们表示 10、11、12、13、14 或 15,而最接近的数字是 9。
Second, the unused patterns might be mapped into legal values. For example, the unused patterns might all be converted to 9, under the theory that they represent 10, 11, 12, 13, 14, or 15, and the closest digit is 9.
或者,它们可以被解码为 2、3、4、5、6 或 7,通过将初始比特设置为 0,理论上第一个比特可能已被破坏。这些理论都不是特别有吸引力,但在设计一个使用 BCD 的系统时,必须提供某种这样的处理措施。
Or they might be decoded as 2, 3, 4, 5, 6, or 7, by setting the initial bit to 0, under the theory that the first bit might have gotten corrupted. Neither of these theories is particularly appealing, but in the design of a system using BCD, some such action must be provided.
2.2.2 遗传密码
另一个将未使用的模式映射为合法值的例子是遗传密码,如第2.7节所述。蛋白质由长链的氨基酸组成,共有$$种不同类型,每种包含$$到$$个原子。生物体内有数百万种不同的蛋白质,据认为所有的细胞活动都涉及蛋白质。蛋白质在生命过程中必须被制造出来,但很难想象有数百万个专用的化学制造单元,每种类型的蛋白质对应一个。相反,一个通用的机制在DNA(脱氧核糖核酸)和RNA(核糖核酸)分子中包含的描述(可以将其视为蓝图)的指导下组装蛋白质。DNA和RNA都是由小“核苷酸”组成的线性链;一个DNA分子可能由超过一亿个这样的核苷酸组成。DNA中有四种类型的核苷酸,每种包含一些共同的结构和四种不同的碱基之一,分别是腺嘌呤(Adenine)、胞嘧啶(Cytosine)、鸟嘌呤(Guanine)和胸腺嘧啶(Thymine)。在RNA中,结构类似,只是胸腺嘧啶被尿嘧啶(Uracil)取代。
遗传密码描述了核苷酸序列如何指定氨基酸。基于这种关系,可以通过线性核苷酸序列指定整个蛋白质。注意,蛋白质的编码描述本身并不比蛋白质本身更小或更简单;事实上,指定蛋白质所需的原子数量比蛋白质本身的原子数量还要多。标准化表示的价值在于,它允许相同的装配装置在不同时间制造不同的蛋白质。
由于有四种不同的核苷酸,每种核苷酸最多可以指定$$种不同的氨基酸。$$个核苷酸的序列可以指定$$种不同的氨基酸。但这还不够——蛋白质中使用了20种不同的氨基酸——因此需要$$个核苷酸的序列。这种序列称为密码子(codon)。有$$种不同的密码子,足够指定$$种氨基酸。剩余的容量用于为大多数氨基酸提供多种组合,从而提供一定程度的**鲁棒性**。例如,氨基酸丙氨酸有4个密码子,包括所有以GC开头的密码子,因此可以忽略第三个核苷酸,这样一来,如果第三个核苷酸发生变异,就不会影响任何生物功能。实际上,$$种氨基酸中有$$种具有这种性质,即**第三个**核苷酸是“无关紧要”的。(事实上,由于一种被称为“摇摆效应”的影响,第三个核苷酸在转录过程中比其他两个更容易受到破坏。)
对遗传密码的检查表明,有$$个密码子(UAA、UAG和UGA)不指定任何氨基酸。这三个密码子表示蛋白质的结束。这样的“终止密码”是必要的,因为不同的蛋白质有不同的长度。密码子AUG指定氨基酸甲硫氨酸,同时也表示蛋白质的开始;所有蛋白质链都以甲硫氨酸开始。许多人为编码具有这种性质,即某些比特序列表示数据,但有一些保留用于控制信息。
Another example of mapping unused patterns into legal values is provided by the Genetic Code, described in Section 2.7. A protein consists of a long sequence of amino acids, of 20 different types, each with between 10 and 27 atoms. Living organisms have millions of different proteins, and it is believed that all cell activity involves proteins. Proteins have to be made as part of the life process, yet it would be difficult to imagine millions of special-purpose chemical manufacturing units, one for each type of protein. Instead, a generalpurpose mechanism assembles the proteins, guided by a description (think of it as a blueprint) that is contained in DNA (deoxyribonucleic acid) and RNA (ribonucleic acid) molecules. Both DNA and RNA are linear chains of small "nucleotides;" a DNA molecule might consist of more than a hundred million such nucleotides. In DNA there are four types of nucleotides, each consisting of some common structure and one of four different bases, named Adenine, Cytosine, Guanine, and Thymine. In RNA the structure is similar except that Thymine is replaced by Uracil.
The Genetic Code is a description of how a sequence of nucleotides specifies an amino acid. Given that relationship, an entire protein can be specified by a linear sequence of nucleotides. Note that the coded description of a protein is not by itself any smaller or simpler than the protein itself; in fact, the number of atoms needed to specify a protein is larger than the number of atoms in the protein itself. The value of the standardized representation is that it allows the same assembly apparatus to fabricate different proteins at different times.
Since there are four different nucleotides, one of them can specify at most four different amino acids. A sequence of two can specify 16 different amino acids. But this is not enough - there are 20 different amino acids used in proteins - so a sequence of three is needed. Such a sequence is called a codon. There are 64 different codons, more than enough to specify 20 amino acids. The spare capacity is used to provide more than one combination for most amino acids, thereby providing a degree of robustness. For example, the amino acid Alanine has 4 codes including all that start with GC; thus the third nucleotide can be ignored, so a mutation which changed it would not impair any biological functions. In fact, eight of the 20 amino acids have this same property that the third nucleotide is a "don't care." (It happens that the third nucleotide is more likely to be corrupted during transcription than the other two, due to an effect that has been called "wobble.")
An examination of the Genetic Code reveals that three codons (UAA, UAG, and UGA) do not specify any amino acid. These three signify the end of the protein. Such a "stop code" is necessary because different proteins are of different length. The codon AUG specifies the amino acid Methionine and also signifies the beginning of a protein; all protein chains begin with Methionine. Many man-made codes have this property, that some bit sequences designate data but a few are reserved for control information.
2.2.3 电话区号
第三种使用剩余容量的方法是将其预留以备将来扩展。
The third way in which spare capacity can be used is by reserving it for future expansion.
当AT&T于1947年开始在美国和加拿大使用电话区号(1951年对公众开放使用)时,这些区号包含三位数字,并有三个限制条件:
第一个数字不能是0或1,以避免与拨0接通接线员的冲突,1则可能是由于故障的黏性旋转拨号盘或未知原因的临时电路中断(或如今表示拨号者确认呼叫可能是收费电话)。
中间的数字只能是0或1(0用于只有一个区号的州和省份,1用于有多个区号的州和省份)。这一限制允许区号与交换机区分开来(当时交换机表示为一个词的前两个字母和一个数字;如今交换机用三位数字表示)。
最后两位数字不能相同(abb形式的号码更容易记住,因此更有价值)——这样,x11拨号序列如911(紧急呼叫)、411(电话查询)和611(维修服务)用于本地服务得到了保护。这也允许后来采用500(跟随我)、600(加拿大无线)、700(互联服务)、800(免费电话)和900(增值信息服务)。
因此,最初只可能有$$个区号。最初使用了$$个,并分配给旋转拨号盘上拨号更快的地区,流入交通量较大的地区(例如曼哈顿的212区号)。剩余的$$个区号被预留用于后续分配。
这$$个新区号的池子足以维持四十多年。最终,当需要超过$$个区号时,通过放宽中间数字仅为0或1的限制,创建了新的区号。1995年1月15日,第一个中间数字不是0或1的区号在阿拉巴马州投入使用。现行的区号限制是第一个数字不能是0或1,中间数字不能是9,最后两位数字不能相同。到2000年初,新增了$$个区号,这种巨大需求部分是由于电话网络用于其他服务如传真和手机的扩展,部分是由于加勒比海岛等地区的政治压力,它们希望拥有自己的区号,部分是由于大量新电话公司提供服务,因此需要在每个收费区至少拥有一个完整的交换机。一些人认为北美编号计划(NANP)将在2025年前用完区号,已有多种应对方案。
考虑到整个北美的每个电话交换机都需要升级,包括更新的软件以及在某些情况下需要新硬件,1995年的过渡非常顺利。总体而言,公众没有意识到这一变化的重要性。这是由于北美电话服务的普遍高质量,以及行业的紧密协调。唯一的问题是一些由独立供应商设计的PBX(私人分支交换机)未能及时升级。自1995年以来,北美电信行业发生了巨大变化:现在控制更少,竞争更多,提供的服务种类更广泛。未来的编号计划变化肯定会导致更大的混乱和公众的不便。
When AT&T started using telephone Area Codes for the United States and Canada in 1947 (they were made available for public use in 1951), the codes contained three digits, with three restrictions.
The first digit could not be 0 or 1, to avoid conflicts with 0 connecting to the operator, and 1 being an unintended effect of a faulty sticky rotary dial or a temporary circuit break of unknown cause (or today a signal that the person dialing acknowledges that the call may be a toll call)
The middle digit could only be a 0 or 1 (0 for states and provinces with only one Area Code, and 1 for states and provinces with more than one). This restriction allowed an Area Code to be distinguished from an exchange (an exchange, the equipment that switched up to 10,000 telephone numbers, was denoted at that time by the first two letters of a word and one number; today exchanges are denoted by three digits).
The last two digits could not be the same (numbers of the form abb are more easily remembered and therefore more valuable)—thus x11 dialing sequences such as 911 (emergency), 411 (directoryassistance), and 611 (repair service) for local services were protected. This also permitted the later adoption of 500 (follow-me), 600 (Canadian wireless), 700 (interconnect services), 800 (toll-free calls), and 900 (added-value information services).
As a result only 144 Area Codes were possible. Initially 86 were used and were assigned so that numbers more rapidly dialed on rotary dials went to districts with larger incoming traffic (e.g., 212 for Manhattan).The remaining 58 codes were reserved for later assignment.
This pool of 58 new Area Codes was sufficient for more than four decades. Finally, when more than 144 Area Codes were needed, new Area Codes were created by relaxing the restriction that the middle digit be only 0 or 1. On January 15, 1995, the first Area Code with a middle digit other than 0 or 1 was put into service, in Alabama. The present restrictions on area codes are that the first digit cannot be 0 or 1, the middle digit cannot be 9, and the last two digits cannot be the same. As of the beginning of 2000, 108 new Area Codes had been started, this great demand due in part to expanded use of the telephone networks for other services such as fax and cell phones, in part to political pressure from jurisdictions such as the Caribbean islands that wanted their own area codes, and in part by the large number of new telephone companies offering service and therefore needing at least one entire exchange in every rate billing district.Some people believe that the North American Numbering Plan (NANP) will run out of area codes before 2025, and there are various proposals for how to deal with that.
The transition in 1995 went remarkably smoothly, considering that every telephone exchange in North America required upgrading, both in revised software and, in some cases, new hardware. By and large the public was not aware of the significance of the change. This was a result of the generally high quality of North American telephone service, and the fact that the industry was tightly coordinated. The only glitches seem to have been that a few PBX (Private Branch eXchanges) designed by independent suppliers were not upgraded in time. Since 1995 the telecommunications industry in North America has changed greatly: it now has less central control, much more competition, and a much wider variety of services offered. Future changes in the numbering plan will surely result in much greater turmoil and inconvenience to the public.
2.2.4 IP地址
另一个需要为未来使用预留容量的例子是IP(互联网协议)地址,如第2.8节所述。IPv4地址的形式为x.x.x.x,其中每个x是$$到$$之间的数字。因此,每个IP地址可以用总共$$位来编码。IP地址由互联网编号分配机构(IANA, Internet Assigned Numbers Authority)分配,网址为http://www.iana.org/。
互联网兴趣的爆发导致对IP地址的需求大增,参与互联网开发的组织(曾被分配了大量编号的组织)开始觉得自己在囤积一种宝贵的资源。这些组织包括AT&T、BBN、IBM、Xerox、HP、DEC、Apple、MIT、福特、斯坦福大学、BNR、保德信、杜邦、默克、美国邮政局及若干美国国防部机构(见第2.8节)。美国电力行业以EPRI(电力研究院)的形式,要求为每个计费家庭或办公室套间分配大量的互联网地址,以便将来由远程抄表设备使用。互联网工程任务组(IETF, Internet Engineering Task Force,网址为http://www.ietf.org/ )认识到互联网地址的需求比最初设想的要更广泛、更细致——例如,当冰箱、烤箱、电话和加热炉等设备能够连接互联网时,需要为它们分配地址,而且每辆汽车和卡车内可能需要几个地址,也许每个微处理器和传感器都需要一个地址。结果是开发了IPv6,其中每个地址仍然是x.x.x.x的形式,但每个x现在是$$到$$之间的$$位数字。因此,新IP地址将需要$$位。现有地址不需要更改,但所有网络设备都必须更改以适应更长的地址。新分配包括为未来扩展预留的大块地址,有人(幽默地)说有些地址块是为其他星球预留的。地址空间的大小足以容纳每台个人计算机的唯一硬件标识符,一些隐私倡导者指出,IPv6可能使匿名网页浏览变得不可能。
Another example of the need to reserve capacity for future use is afforded by IP (Internet Protocol) addresses, which is described in Section 2.8. These are (in version 4) of the form x.x.x.x where each x is a number between 0 and 255, inclusive. Thus each Internet address can be coded in a total of 32 bits. IP addresses are assigned by the Internet Assigned Numbers Authority, http://www.iana.org/, (IANA).
The explosion of interest in the Internet has created a large demand for IP addresses, and the organizations that participated in the development of the Internet, who had been assigned large blocks of numbers, began to feel as though they were hoarding a valuable resource. Among these organizations are AT&T, BBN, IBM, Xerox, HP, DEC, Apple, MIT, Ford, Stanford, BNR, Prudential, duPont, Merck, the U.S. Postal Service, and several U.S. DoD agencies (see Section 2.8). The U.S. electric power industry, in the form of EPRI (Electric Power Research Institute), requested a large number of Internet addresses, for every billable household or office suite, for eventual use by remote meter reading equipment. The Internet Engineering Task Force, http://www.ietf.org/, (IETF) came to realize that Internet addresses were needed on a much more pervasive and finer scale than had been originally envisioned—for example, there will be a need for addresses for appliances such as refrigerators, ovens, telephones, and furnaces when these are Internet-enabled, and there will be several needed within every automobile and truck, perhaps one for each microprocessor and sensor on the vehicle. The result has been the development of version 6, IPv6, in which each address is still of the form x.x.x.x, but each x is now a 32-bit number between 0 and 4,294,967,295 inclusive. Thus new Internet addresses will require 128 bits. Existing addresses will not have to change, but all the network equipment will have to change to accommodate the longer addresses. The new allocations include large blocks which are reserved for future expansion, and it is said (humorously) that there are blocks of addresses set aside for use by the other planets. The size of the address space is large enough to accommodate a unique hardware identifier for each personal computer, and some privacy advocates have pointed out that IPv6 may make anonymous Web surfing impossible.
2.2.5 ASCII
剩余容量的第四种用途是将其中一部分用于表示格式化或控制操作。
A fourth use for spare capacity in codes is to use some of it for denoting formatting or control operations.
许多编码包含不是数据而是控制代码的编码模式。例如,遗传密码在$$种密码子中包括$$种模式作为终止蛋白质生产的终止密码。
Many codes incorporate code patterns that are not data but control codes. For example, the Genetic Code includes three patterns of the 64 as stop codes to terminate the production of the protein.
最常用的文本字符编码,ASCII(美国信息交换标准代码,如第2.5节所述)明确保留了其$$个代码中的$$个用于控制,仅有$$个用于字符。这$$个字符包括英语字母的$$个大写字母和$$个小写字母,$$个数字,$$个空格以及$$个标点符号。
The most commonly used code for text characters, ASCII (American Standard Code for Information Interchange, described in Section 2.5) reserves 33 of its 128 codes explicitly for control, and only 95 for characters. These 95 include the 26 upper-case and 26 lower-case letters of the English alphabet, the 10 digits, space, and 32 punctuation marks.
2.3 代码的扩展
许多代码是由人类设计的。有时这些代码极其健壮、简单、易于使用并且可扩展;有时它们却脆弱、晦涩、复杂,甚至连最简单的推广都无法做到。通常,一个简单、实用的代码最初是为了表示少量项目而开发的,由于其成功引起了广泛关注,人们开始在其原始背景之外使用它,以表示更多类型的对象,达到最初未预见的目的。
被推广的代码往往带有其原始背景中的无意偏差。有时结果只是令人发笑,但在其他情况下,这些偏差使代码难以使用。
Many codes are designed by humans. Sometimes codes are amazingly robust, simple, easy to work with, and extendable. Sometimes they are fragile, arcane, complex, and defy even the simplest generalization.Often a simple, practical code is developed for representing a small number of items, and its success draws attention and people start to use it outside its original context, to represent a larger class of objects, for purposes not originally envisioned.
Codes that are generalized often carry with them unintended biases from their original context. Sometimes the results are merely amusing, but in other cases such biases make the codes difficult to work with.
一个相对无害的偏差的例子是ASCII码中有两个字符最初是用来被忽略的。ASCII码最初是用于纸带上的7位孔模式,用于向电传打字机传输信息。纸带最初没有孔(除了用于对齐和进带的一系列小孔),通过打孔器传输。纸带可以从接收到的传输中打孔,也可以通过人类在键盘上打字来打孔。这种打孔操作的碎屑被称为“chad”。纸带的开头部分没有打孔,因此实际上表示了一系列长度不确定的字符0000000(0表示没有孔)。当然,当纸带被读取时,开头部分应被忽略,因此按惯例字符0000000被称为NUL并被忽略。
后来,当ASCII在计算机中使用时,不同系统对NUL的处理方式不同。Unix在某些情况下将NUL视为单词的结尾,而这种用法会干扰字符被赋予数值解释的应用程序。另一个最初被用来忽略的ASCII码是DEL,1111111。这种惯例对打字员很有帮助,他们可以通过回退纸带并打出所有孔来“擦除”错误。在现代环境中,DEL通常被视为破坏性的退格,但过去一些文本编辑器将DEL用作向前删除字符,有时它则被简单地忽略。
An example of a reasonably benign bias is the fact that ASCII has two characters that were originally intended to be ignored. ASCII started as the 7-bit pattern of holes on paper tape, used to transfer information to and from teletype machines. The tape originally had no holes (except a series of small holes, always present, to align and feed the tape), and travelled through a punch. The tape could be punched either from a received transmission, or by a human typing on a keyboard. The debris from this punching operation was known as "chad." The leader (the first part of the tape) was unpunched, and therefore represented, in effect, a series of the character 0000000 of undetermined length (0 is represented as no hole). Of course when the tape was read the leader should be ignored, so by convention the character 0000000 was called NUL and was ignored.
Later, when ASCII was used in computers, different systems treated NULs differently. Unix treats NUL as the end of a word in some circumstances, and this use interferes with applications in which characters are given a numerical interpretation. The other ASCII code which was originally intended to be ignored is DEL, 1111111. This convention was helpful to typists who could "erase" an error by backing up the tape and punching out every hole. In modern contexts DEL is often treated as a destructive backspace, but some text editors in the past have used DEL as a forward delete character, and sometimes it is simply ignored.
ASCII携带的一个更严重的偏差是使用两个字符,CR(回车)和LF(换行),来移动到新的打印行。在电传打字机中,物理机制有单独的硬件将纸张(在连续卷上)向上移动,并将打印元素重新定位到左边缘。设计演变为ASCII的代码的工程师们肯定认为,允许这些操作单独调用是件好事。
他们无法想象当ASCII适应不同硬件且不需要分别调用CR或LF来移动打印位置时,会给后代带来多少痛苦。不同的计算系统做法不同——Unix使用LF作为新行并忽略CR,Macintosh(至少在OS X之前)使用CR并忽略LF,而DOS/Windows需要两者。这种不兼容性持续带来严重的挫败感和错误。例如,在使用FTP(文件传输协议)传输文件时,CR和LF应根据目标平台转换为适合的文本文件,但不适用于二进制文件。一些FTP程序从文件扩展名(文件名最后一个点后的部分)推断文件类型(文本或二进制)。其他程序检查文件内部并计算“特殊字符”的数量。还有一些程序依赖人工输入。这些技术通常有效,但并非总是有效。文件扩展名约定并非普遍遵循。人类会犯错误。如果文件的一部分是文本,另一部分是二进制呢?
A much more serious bias carried by ASCII is the use of two characters, CR (carriage return) and LF (line feed), to move to a new printing line. The physical mechanism in teletype machines had separate hardware to move the paper (on a continuous roll) up, and reposition the printing element to the left margin. The engineers who designed the code that evolved into ASCII surely felt they were doing a good thing by permitting these operations to be called for separately.
They could not have imagined the grief they have given to later generations as ASCII was adapted to situations with different hardware and no need to move the point of printing as called for by CR or LF separately. Different computing systems do things differently—Unix uses LF for a new line and ignores CR, Macintoshes (at least prior to OS X) use CR and ignore LF, and DOS/Windows requires both. This incompatibility is a continuing, serious source of frustration and errors. For example, in the transfer of files using FTP (File Transfer Protocol) CR and LF should be converted to suit the target platform for text files, but not for binary files. Some FTP programs infer the file type (text or binary) from the file extension (the part of the file name following the last period). Others look inside the file and count the number of "funny characters." Others rely on human input. These techniques usually work but not always. File extension conventions are not universally followed. Humans make errors. What if part of a file is text and part binary?
2.4 固定长度和可变长度编码
在编码设计的早期阶段,必须决定是用相同数量的比特(固定长度)来表示所有符号,还是让某些符号使用比其他符号更短的编码(可变长度)。这两种方案各有优势。
A decision that must be made very early in the design of a code is whether to represent all symbols with codes of the same number of bits (fixed length) or to let some symbols use shorter codes than others
(variable length). There are advantages to both schemes.
固定长度编码通常更容易处理,因为编码器和解码器事先知道涉及多少比特,只需要设置或读取值即可。对于可变长度编码,解码器需要一种方法来确定一个符号的编码何时结束,下一个符号的编码何时开始。
Fixed-length codes are usually easier to deal with because both the coder and decoder know in advance how many bits are involved, and it is only a matter of setting or reading the values. With variable-length codes, the decoder needs a way to determine when the code for one symbol ends and the next one begins.
固定长度编码可以通过并行传输来支持,其中比特同时从编码器传输到解码器,例如使用多根电线传输电压。这种方法应该与编码信息的串行传输相对比,在串行传输中,一根电线发送一串比特,解码器必须决定一个符号的比特何时结束,下一个符号的比特何时开始。如果解码器混淆了,或者在流开始后查看比特,它可能不知道。这被称为“帧错误”。为消除帧错误,符号之间通常发送停止位;通常通过串行线发送的ASCII有1或2个停止位,通常赋值为$$。因此,如果解码器步调不一致,它最终会在假定为停止位的位置找到一个$$,然后尝试重新同步。尽管理论上帧错误可能持续很长时间,但在实际使用中,使用停止位效果很好。
Fixed-length codes can be supported by parallel transmission, in which the bits are communicated from the coder to the decoder simultaneously, for example by using multiple wires to carry the voltages. This approach should be contrasted with serial transport of the coded information, in which a single wire sends a stream of bits and the decoder must decide when the bits for one symbol end and those for the next symbol start. If a decoder gets mixed up, or looks at a stream of bits after it has started, it might not know. This is referred to as a "framing error." To eliminate framing errors, stop bits are often sent between symbols; typically ASCII sent over serial lines has 1 or 2 stop bits, normally given the value 0. Thus if a decoder is out of step, it will eventually find a 1 in what it assumed should be a stop bit, and it can try to resynchronize.Although in theory framing errors could persist for long periods, in practice use of stop bits works well.
2.4.1 摩尔斯电码
可变长度编码的一个例子是摩尔斯电码,它是为电报机开发的。字母、数字和标点符号的编码是由点和划以及它们之间的短间隔组成的。参见第2.9节。
解码器通过注意下一个点或划之前的时间长度来判断单个字符编码的结束。字符内的间隔长度是一个点的长度,字符间的间隔较长,是一个划的长度。单词间的间隔更长。
An example of a variable-length code is Morse Code, developed for the telegraph. The codes for letters, digits, and punctuation are sequences of dots and dashes with short-length intervals between them. See Section 2.9.
The decoder tells the end of the code for a single character by noting the length of time before the next dot or dash. The intra-character separation is the length of a dot, and the inter-character separation is longer, the length of a dash. The inter-word separation is even longer.
2.5 详解:ASCII
ASCII,即“美国信息交换标准代码”,是由美国国家标准协会(ANSI)于1963年引入的。这是最常用的字符编码。
ASCII是一个$$比特的编码,如表2.2所示,代表了$$个控制字符和$$个打印字符(包括空格)。控制字符用于表示特殊条件,如表2.3所述。
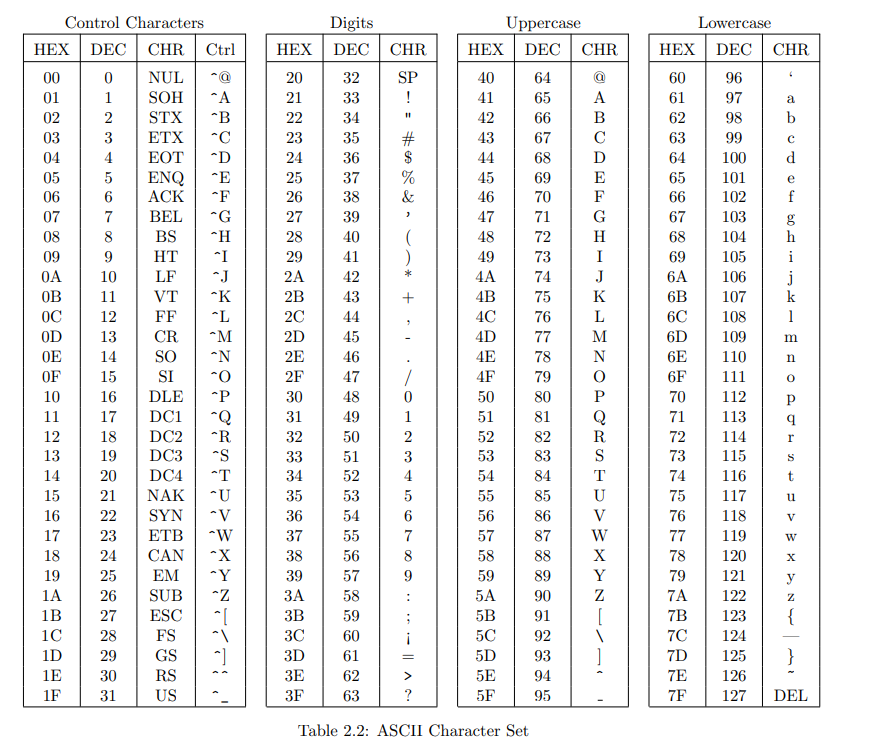
ASCII, which stands for "The American Standard Code for Information Interchange," was introduced by the American National Standards Institute (ANSI) in 1963. It is the most commonly used character code.
ASCII is a seven-bit code, representing the 33 control characters and 95 printing characters (including space) in Table 2.2. The control characters are used to signal special conditions, as described in Table 2.3.
迈向8位
在8位上下文中,ASCII字符前面跟随一个$$,因此可以认为是一个较大编码的“下半部分”。由代码$$到$$之间表示的128个字符(有时错误地称为“高ASCII”或“扩展ASCII”)在不同的上下文中有不同的定义。在许多操作系统中,它们包括带重音的西欧字母和各种额外的标点符号。在IBM PC中,它们包括线条绘制字符。Mac电脑使用(并且仍在使用)不同的编码。
幸运的是,现在人们已经意识到计算机平台互操作性的必要性,因此更加普遍的标准开始受到青睐。用于网页的最常用编码是$$(ISO-Latin),它使用$$到$$之间的96个代码表示西欧语言的各种带重音字母和标点符号,以及一些其他符号。$$到$$之间的32个字符在$$中保留为控制字符。
自然界厌恶真空。大多数人不希望有$$个更多的控制字符(事实上,在$$位ASCII的$$个控制字符中,只有大约$$个在文本中经常使用)。因此,对于使用$$到$$有无数的想法。最广泛使用的约定是微软的Windows代码页$$(Latin I),它与$$(ISO-Latin)相同,除了32个控制代码中的27个被分配给打印字符,其中之一是$$,即欧元货币符号。并非所有平台和操作系统都识别$$,因此文档,特别是网页,需要特别注意。

In an 8-bit context, ASCII characters follow a leading 0, and thus may be thought of as the "bottom half" of a larger code. The 128 characters represented by codes between HEX 80 and HEX FF (sometimes incorrectly called "high ASCII" of "extended ASCII") have been defined differently in different contexts. On many operating systems they included the accented Western European letters and various additional
punctuation marks. On IBM PCs they included line-drawing characters. Macs used (and still use) a different encoding.
Fortunately, people now appreciate the need for interoperability of computer platforms, so more universal standards are coming into favor. The most common code in use for Web pages is ISO-8859-1 (ISO-Latin)
which uses the 96 codes between HEX A0 and HEX FF for various accented letters and punctuation of Western European languages, and a few other symbols. The 32 characters between HEX 80 and HEX 9F
are reserved as control characters in ISO-8859-1.
Nature abhors a vacuum. Most people don't want 32 more control characters (indeed, of the 33 control characters in 7-bit ASCII, only about ten are regularly used in text). Consequently there has been no end of ideas for using HEX 80 to HEX 9F. The most widely used convention is Microsoft's Windows Code Page 1252
(Latin I) which is the same as ISO-8859-1 (ISO-Latin) except that 27 of the 32 control codes are assigned to printed characters, one of which is HEX 80, the Euro currency character. Not all platforms and operating systems recognize CP-1252, so documents, and in particular Web pages, require special attention.
超越8位
为了表示亚洲语言,需要更多的字符。目前适当标准的制定正在积极进行中,一般认为需要表示的字符总数少于$$。这很幸运,因为这么多不同的字符可以用16位或2字节来表示。为了保持在这个数字以内,一些中文方言的书写版本必须共享看起来相似的符号。
目前最有希望的2字节标准字符编码被称为Unicode。
To represent Asian languages, many more characters are needed. There is currently active development of appropriate standards, and it is generally felt that the total number of characters that need to be represented is less that 65,536. This is fortunate because that many different characters could be represented in 16 bits, or 2 bytes. In order to stay within this number, the written versions of some of the Chinese dialects must share symbols that look alike.
The strongest candidate for a 2-byte standard character code today is known as Unicode.
参考资料
有许多网页提供了ASCII图表,涵盖了世界上所有语言的扩展。
其中比较有用的有:
Jim Price,提供了PC和Windows 8位图表,并包含几个进一步的链接 [http://www.jimprice.com/jim-asc.shtml](http://www.jimprice.com/jim-asc.shtml)
字符编码简史,包括对扩展到亚洲语言的讨论 [http://tronweb.super-nova.co.jp/characcodehist.html](http://tronweb.super-nova.co.jp/characcodehist.html)
Unicode主页 [http://www.unicode.org/](http://www.unicode.org/)
Windows CP-1252标准,权威版本 [http://www.microsoft.com/globaldev/reference/sbcs/1252.htm](http://www.microsoft.com/globaldev/reference/sbcs/1252.htm)
CP-1252与以下内容的比较: