参考资料
最近用 langchain 搭了一个简易的RAG系统自动处理了一些工作的应用,顺便学了些原理。我把具体工作内容删了(例子),只留下原理部分分享出来(其实就是把论文里的内容复制粘贴一遍)。
RAG
Embedding
一些RAG应用:
RAG原理
阅读gpt3论文 https://arxiv.org/pdf/2005.14165 可知,大模型内部参数是固定的,不会实时更新;而且有“幻觉”现象,产出的内容不可全信。
RAG相关论文 https://arxiv.org/pdf/2507.18910 也提到: Traditional LLM-based generation relies solely on the model’s internal parameters for knowledge, which can lead to hallucinations and factual inaccuracies when the model’s training data does not adequately cover the query’s topic
针对大模型“无法实时更新模型”这个局限性,RAG技术应运而生。

1
2
3



Retrieval-Augmented Generation,检索-增强-生成。
数学语言描述:

图像语言描述:
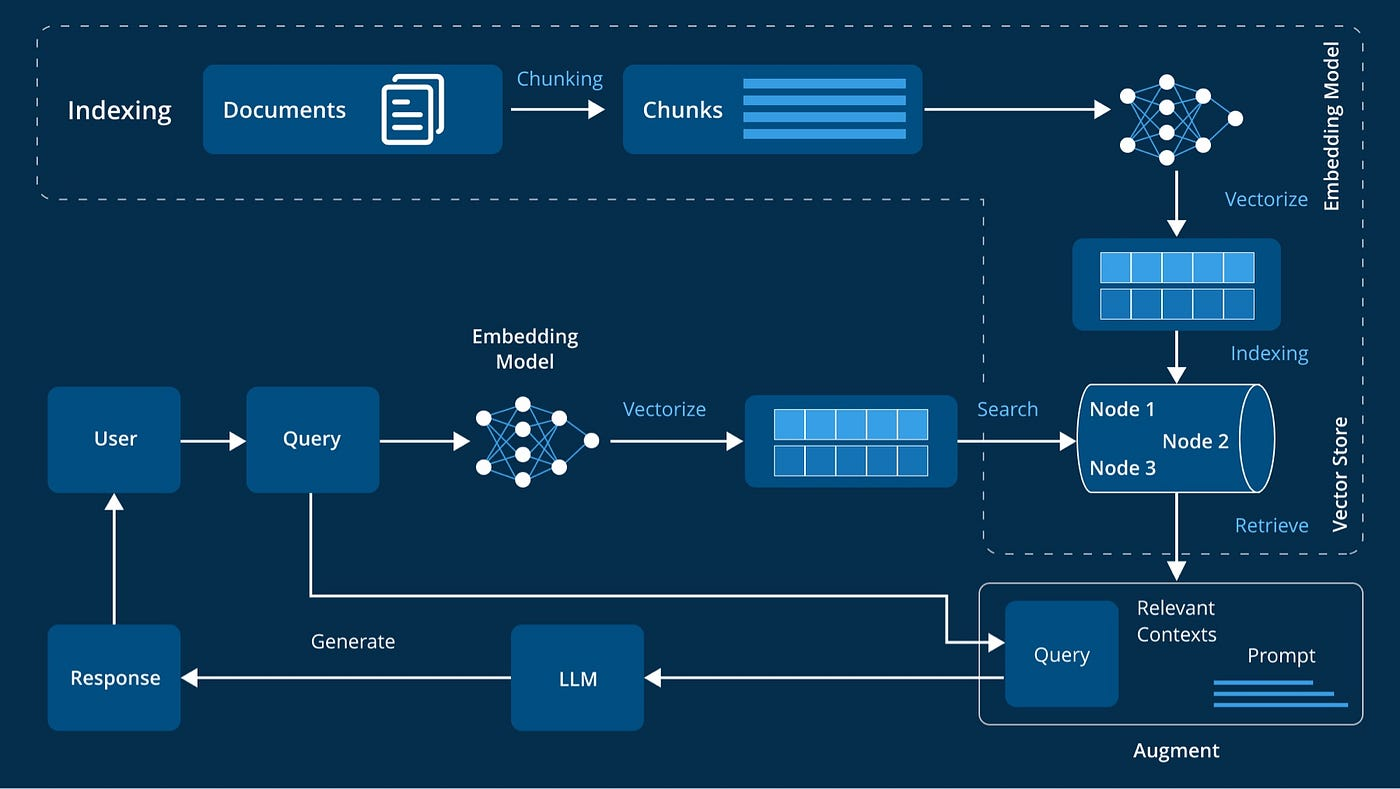
(openclaw 的 chunk size 是 700个字符)

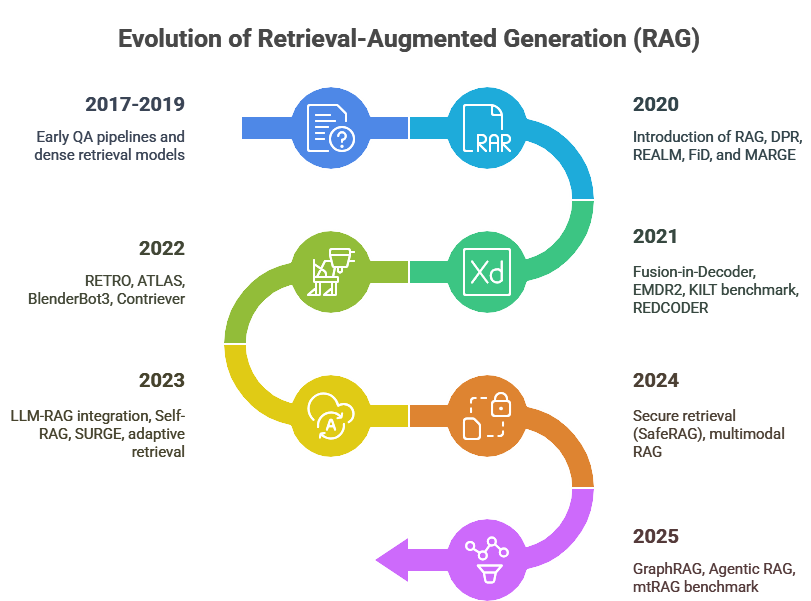
Embedding原理
为什么采用向量,为什么不直接通过文本检索?

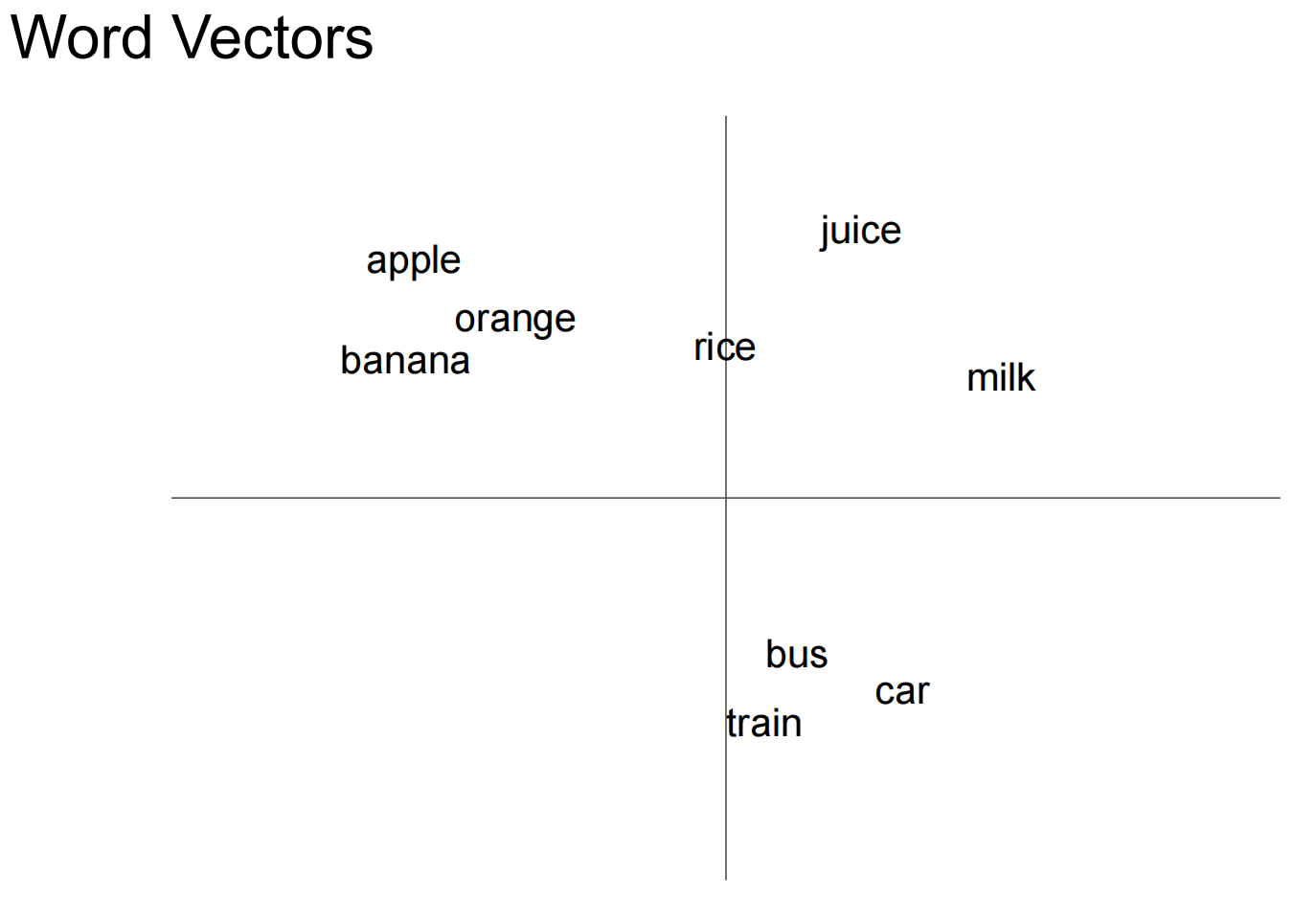
word embeddings 最常见
embeddings for sentences, paragraphs, or whole documents 适用于RAG

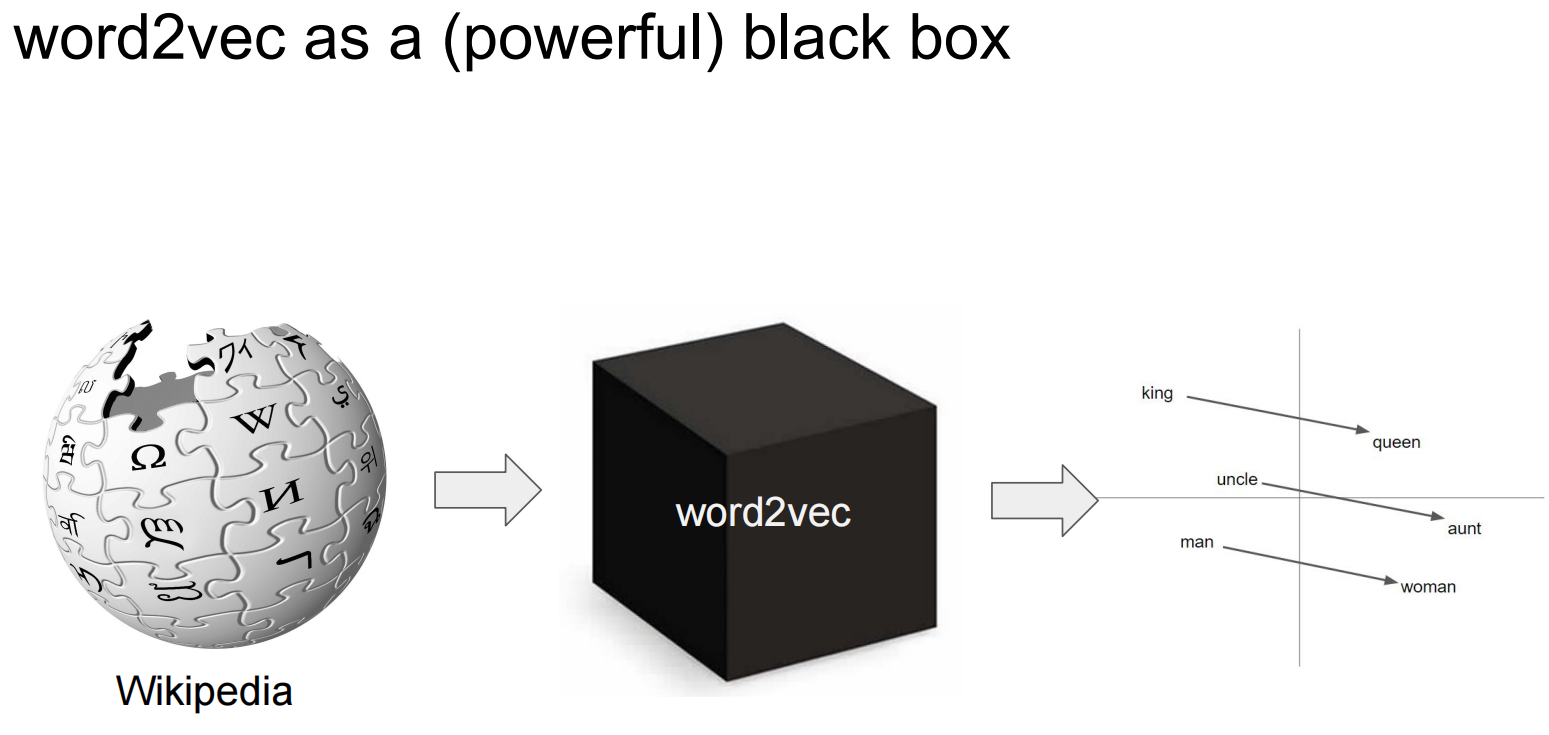
中文翻译:词在向量空间中的分布式表示通过将相似的词分组,帮助学习算法在自然语言处理任务中实现更好的性能。

中文翻译:使用神经网络计算的词向量非常有趣,因为学习到的向量明确地编码了许多语言规律和模式。令人惊讶的是,许多这些模式可以表示为线性变换。例如,向量计算 vec("马德里") - vec("西班牙") + vec("法国") 的结果比任何其他词向量都更接近 vec("巴黎")

中文翻译:词表示受到其无法表示非词汇组合的习语短语的限制。例如,"Boston Globe"(波士顿环球报)是一份报纸,因此它不是"Boston"(波士顿)和"Globe"(全球)两个词意义的自然组合。因此,使用向量来表示整个短语使Skip-gram模型表达能力大大增强。其他旨在通过组合词向量来表示句子意义的技术,如递归自编码器
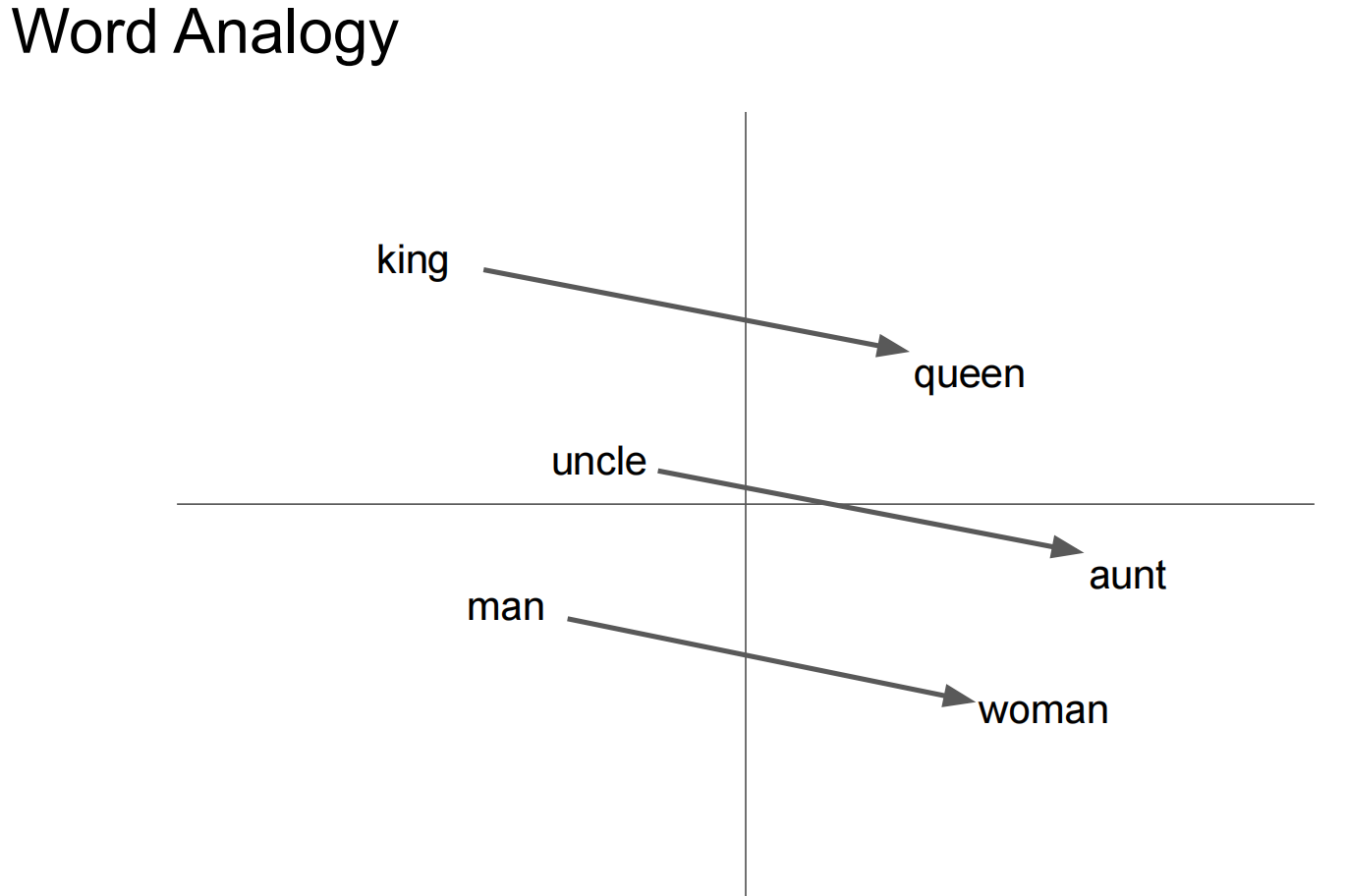
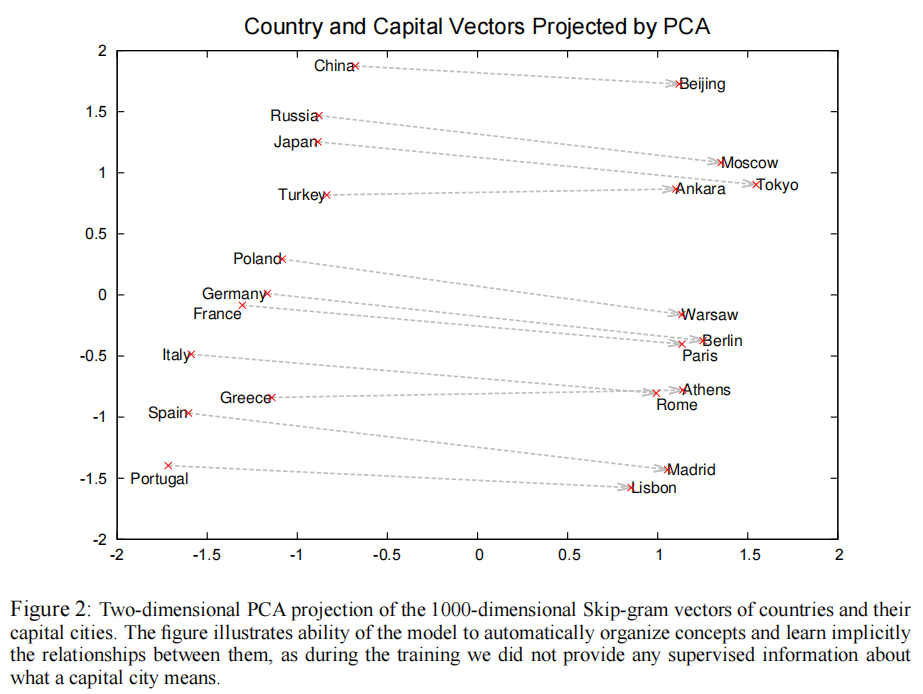
https://ronxin.github.io/wevi/
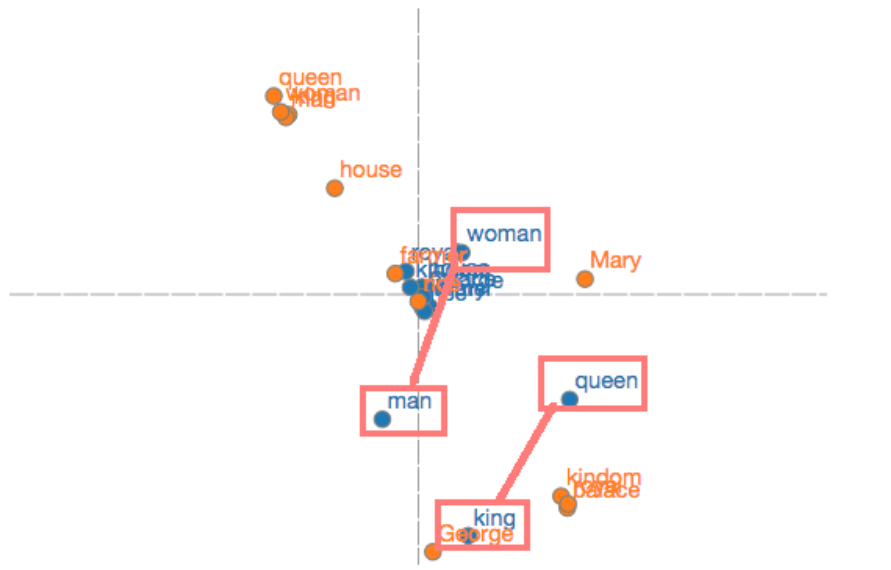
OpenClaw的记忆机制
OpenClaw记忆机制 https://docs.openclaw.ai/zh-CN/concepts/memory

