1.预测机器
预测机器
新学科视角
清晨,我还在卧室中熟睡,一大堆令人生畏的工作文件放在床边。我缓缓从睡梦中醒来,听到了一阵轻柔的鸟鸣声。或者,至少一开始貌似是这样的。但我很快发现我错了。我努力倾听,意识到四周是死一般的寂静。连我家猫咪清晨讨要食物的叫声都没有打破这片寂静。原来鸟鸣声只是我的幻听。
幸运的是,我对此有一个简单的解释。我爱人为了让早上醒来的过程更加舒缓,最近决定使用一款会播放鸟鸣声而非传统闹铃声的智能手机应用程序。这款应用程序的闹铃声一开始是轻柔的鸟鸣,然后非常缓慢地增强为近乎鸟儿晨间的大合唱。当天早上,闹钟实际上并没有响起,因为时间还太早。而且,真正的鸟鸣声也从未透过双层玻璃传入房间。但我已经习惯在那缓慢增强的鸟鸣声中醒来,以至于我的大脑开始对我耍起了花招。我现在发现自己经常在闹钟响起之前就已经醒了,似乎已经听到了那些预先录制的鸟鸣声的轻柔前奏。
关于幻觉的早期报告,可见:Ellison, D. G., “Hallucinations Produced by Sensory Conditioning,”Journal of Experimental Psychology 28 (1941): 1–20。通过将“看到灯泡微微亮起”与“听到简单的音调”配对并反复向受试者呈现,实验者诱导了受试者随后的幻觉体验:接受“训练”后,听到同样音调的受试者会报告自己看见了很微弱的光。
**这是真正的幻听,是由我新形成的对在轻柔鸟鸣声中苏醒的强烈期望而引起的。**我对这种幻听的倾向可能并没有什么凶险之处。人们早就知道,适当的训练会很容易诱发幻觉,无论是幻视还是幻听。 : 1–20。通过将“看到灯泡微微亮起”与“听到简单的音调”配对并反复向受试者呈现,实验者诱导了受试者随后的幻觉体验:接受“训练”后,听到同样音调的受试者会报告自己看见了很微弱的光。") 但我们直到最近才意识到,这些现象(以及许多其他有趣的现象)的背后其实是一幅宏大图景,它正是人类一切体验的核心。
但我们直到最近才意识到,这些现象(以及许多其他有趣的现象)的背后其实是一幅宏大图景,它正是人类一切体验的核心。
我们的主要观点(本书的主题)是:人类的大脑是预测机器。它们是进化而来的器官,从期望与实际感官证据的交织和变化中构建及重构我们的主观体验。根据这一观点,我自己对醒来时可能听到的声音的无意识预测,将我的感知体验朝着那个方向简单地“拽”了一下,造成了短暂的幻听,随着更多信息传入我的感官,幻觉很快得到纠正。这些新信息(表示没有鸟鸣声)生成了“预测误差信号”,至少在这种情况下,这些信号足以修正我的体验,使其与现实一致。对寂静房间的明确体验消除了幻听。但在其他情况下,正如我们将看到的,错误的预测可能会变得根深蒂固,我们也更难接触现实(这本身就是一个复杂而棘手的概念)。即使没有误差,当我们看到事物的“本来面目”时,我们大脑的预测仍然发挥着核心作用。人们越来越认为预测和预测误差是人脑的“通用货币”,正是在它们的动态平衡下,人类的一切主观体验得以形成。
本书正是关于这种平衡的,它构成了一门新兴的科学,颠覆了我们对感知世界的许多已有看法。这门科学的理念是,大脑根据从过往遭遇中了解到的信息,不断地试图猜测外界的(以及我们自身的)事物最有可能是什么样子的。这门新科学认为,我所看见、听见、触摸和感受到的一切反映“隐藏的预测源泉”。如果期望足够强烈,或者(就像闹钟一开始的轻柔鸟鸣声那样)感官证据足够弱,我就可能出错,也就是用大脑对事物应然状态的最佳猜测“覆盖”了部分真实的感觉信息。
这并不意味着成功的感知仅仅是幻觉的一种形式,尽管其机制与幻觉的机制相关。我们不应低估眼睛、耳朵和其他感官搜集的丰富信息。但我们的新科学以一种新颖、别样的方式解释了视觉乃至更普遍的知觉的运作过程,将其视为一种由我们大脑本身的最佳预测引导的过程;而后,我们会根据感官输入对预测进行检查和校正。当预测机器正常运行时,感知不仅取决于传入的感觉信息,而且取决于差异——实际接收的感觉信号与大脑预期的信号间的差异。
大脑不会每次都以初始状态“开机”——即便我一大早刚醒,它也不是白纸一张。预测和期望总是在起作用,主动地构建我们每时每刻的体验。根据这种非传统解释,感知的大脑从来不会单纯被动地回应世界。相反,它积极地尝试产生关于世界的“幻觉”,再以感官输入的证据加以检验。换句话说,大脑一直在绘制一幅图画,当预测与实际输入的感官证据不匹配时,感觉信息的作用主要是对笔触进行微调。
对感知过程的这一新的认识对我们的生活至关重要。它改变了我们看待自身感官证据的应有方式,也影响了我们对自身状态(疼痛、饥饿和其他体验,如感到焦虑或抑郁)的认识。对自身状态的感受同样反映了我们大脑的预测和当前身体信号的复杂混合。这意味着我们有时可以通过改变自己(有意识或无意识)的预测来改变我们的感受。
这并不意味着我们就可以简单地“更好预测自己”,也不意味着我们可以随意改变自己对疼痛或饥饿的体验。但它确实提出了一些原则性的,或许是意想不到的回旋余地,而通过监督和训练,我们可以善加利用。若能谨慎处理,更好地认识预测的力量可以改进我们看待自身医学症状的方式,并提供理解心理健康、心理疾病和神经多样性的新途径。
视觉的智能相机模型
大脑本质上是一台伟大的预测机器,这一理念是近期才出现的。在此之前,人们普遍认为感觉信息主要以“前馈”的方式处理,即由我们的感官获取并直接“正向”传入大脑之中。举一个研究得最为充分的例子,我们曾相信视觉信息会先由双目“登记”,然后以逐步深入的方式在大脑内部进行处理,提取出越发抽象的信息形式。大脑可能先从入射光的模式中提取有关简单特征的信息,如线条、斑点和边缘,然后将它们组合成更大、更复杂的整体。我称之为视觉的智能相机模型。这显然不是一台相机,而是一个高度智能的系统。但和常见的相机一样,影响的流动方向主要是向内的:从双目到大脑。直到在这个过程中某个较晚的节点,生命记忆和世界知识才会参与其中,让你(感知者)得以理解自身所处的世界中的事物。
智能相机模型,即感知的前馈观的各种版本在哲学、神经科学和人工智能领域都颇具影响力。这种观点很直观,因为我们通常认为感知完全是关于从世界到心智的信息流动。这种观点可追溯至1664年出版的笛卡儿的遗作《论人》。笛卡儿将感知描述为内管网络的复杂开合,首先将世界的图像印在感官(如眼睛)上,然后通过由微小通道构成的网络传递至大脑深处。笛卡儿相信,当这些源于外部世界(和身体内部)的印象流入大脑,它们就会被保存在我们的脑海之中,就像手指压入蜡模后,有关其形状的信息就会被保留下来。
马尔的具体观点详见其代表作:Vision: A Computational Investigation into the Human Representation and Processing of Visual Information (Cambridge: MIT Press, 1982)。
我们从未知晓笛卡儿所描述的机制如何运作。但即使更为复杂的科学理解不断出现,笛卡儿的核心思想依然稳固,即感知的大脑是一个相对被动的器官,接收外界感觉传入,而后主要以前馈(从外到内)的方式“处理”它们。这一思想在20世纪晚期的认知神经科学领域得到了广泛认可,或许是因为它似乎可被视为大卫·马尔极具影响力的计算机视觉模型的指导原则。
马尔是一位举足轻重的人物,他在神经科学、计算机视觉和人工智能方面的工作是对认知科学有史以来最为重要的贡献。在马尔的描述中,视觉处理始于检测某些传入信号中的基本要素,例如有序的像素阵列。自此,分层处理逐渐形成更为复杂的理解。例如,下一阶段可能会寻找像素强度相比相邻像素显示出快速变化的地方,这通常是现实世界中边界或边缘的存在线索。随着处理过程逐步推进,一步一步地深入大脑,更多模式被进一步检测到,如表征条纹的重复序列。在这里,视觉是对原始信号进行一系列操作的过程,例如检测边缘或条纹,这些操作逐渐揭示环境中越来越复杂的模式,即传入信号的来源。最终,检测到的复杂模式与知识和记忆相结合,形成一幅关于现实场景的三维图像(尽管值得注意的是,关于这幅图像具体如何形成的难题从未得到令人满意的解答)。
类似研究,参见:Riesenhuber, M., and Poggio, T., “Models of Object Recognition,”Nature Neuroscience 3 (Suppl) (2000): 1199–1204。早期一种重要的前馈观,参见:Hubel, D. H.,and Wiesel, T. N., “Receptive Fields and Functional Architecture in Two Nonstriate Visual Areas (18 and 19) of the Cat,”Journal of Neurophysiology 28 (1965): 229–289。最早揭示前馈观不足之处的一些结论性的实证检验,参见:Egner, T., Monti, J. M., and Summerfield, C., “Expectation and Surprise Determine Neural Population Responses in the Ventral Visual Stream,”Journal of Neuroscience 30(49) (2010): 16601–16608。还可参见:Petro, L., Vizioli,L., and Muckli, L., “Contributions of Cortical Feedback to Sensory Processing in Primary Visual Cortex,”Frontiers in Psychology 5 (2014): 1223。
就像任何其他的计算机模型一样,马尔的计算机模型的独特之处在于明确指出了早期阶段的视觉处理可能涉及的重要计算,尽管关键的最终步骤依然有些神秘莫测。马尔的模型多年来不但是人工视觉领域的标准模型,还是神经科学领域的标准模型。即使到了21世纪,许多学者仍沿袭马尔的方向,认为视觉系统主要是对传入的感觉信息进行前馈分析的工具。
例如,在光进入眼睛后,信号首先传递到外侧膝状体核(LGN),后者将信息传递到被称为V1的区域,但这种信息的前馈只是故事的一小部分。LGN的大部分(可能80%左右)输入其实来自大脑的其他区域,其中大部分自V1向下反馈。有关这些连接的估计,参见:Budd,J. M. L., “Extrastriate Feedback to Primary Visual Cortex in Primates: A Quantitative Analysis of Connectivity,”Proceedings of the Royal Society B: Biological Sciences 265(1998): 1037–1044。另请参见:Raichle, M. E., and Mintun, M. A., “Brain Work and Brain Imaging,”Annual Review of Neuroscience 29 (2006): 449–476。
一些关于行动的预测处理模型的精彩探讨和有力实验演示,参见:Muckli, L., et al., “Contex tual Feedback to Superficial Layers of V1 Report,”Current Biology 25 (2015): 2690–2695。
然而,值得注意的是,马尔的模型中缺少另一个影响方向——一种相反的方向,从大脑深处下行至眼睛和其他感官。据估计,以这种方式向相反方向传递信号的神经元连接数量大幅超过正向传递信号的连接数量,二者的比例在一些区域甚至高达4∶1。 从大脑深处向感官外围传递信息的这种下行连接的作用到底是什么?这种连接方。向与马尔早期计算机模型中描述的执行处理任务所需的连接方向相反,但它直达那些特定区域。
能耗数据引用自:Raichle, M., “The Brain’s Dark Energy,”Science 314 (2006): 1249–1250。
关于“我们几乎一无所知的奇怪架构”,参见:Winston, P., “The Next 50 Years: A Personal View,”Biologically Inspired Cognitive Architectures 1 (2012): 92–99。然而,即便在那时,我们也不像温斯顿所暗示的那样一无所知,因为关于下行布线的真正作用,人们在很久以前就已经有了一些不错的见解。相关实例参见以下注释中的参考资料。
像这样的实际神经线路在安装和维护上是昂贵的。据估计,大脑重量仅占体重的约2%,却耗费了人体全部能量的约20%。 它是迄今为止我们最“昂贵”的自适应配件。然而,我们现在已经知道,大脑能耗的很大一部分主要用于建立和维护一个庞大的下行(和横向)连接网络,不仅覆盖早期视觉处理系统,而且覆盖整个大脑。这是一个真正的谜。它令人费解到足以让人工智能先驱帕特里克·温斯顿在2012年评论说,由于有如此多信息明显向另一个方向(下行)流动,我们面对的是“一个我们几乎一无所知的奇怪架构”。 但是,一旦我们认识到一个大胆的新主张的吸引力,一切就会变得明朗起来:大脑只不过是一台大规模的预测机器。
流向的反转
目前来看,感知的大脑的核心工作原理与智能相机观点基本相反。大脑并非不断耗费大量能量来处理传入的感觉信号,其主要工作其实是学习和维系一种关于身体和世界的模型,这种模型无时无刻不被用于尝试预测感觉信号。这些预测有助于构建我们看到、听到、触及和感受到的一切。当我早上听到并不存在的鸟鸣声时,它们正在工作。当我感受到不在我口袋里的手机振动幻觉时,它们也在工作。但我们将会发现,当我听到真实的鸟鸣声,感受到真实的手机振动,以及看到散落在我大学办公室桌面上的各式物品时,它们也在发挥作用。
预测性大脑是对我们周围世界的一种不断运行的模拟——或者至少是对我们很重要的部分世界的模拟。传入的感觉信息被用于保持模型的真实性——比较预测与感官证据,并在两者不匹配时生成误差信号。尽管这种连接方式带来了高昂的成本,但我们很快将看到不断的预测提高了效能。或许更重要的是,它还使我们能够灵活地以反映当前任务和环境要求的方式调整我们的反应。与从一连串感官线索中稳定提取丰富的世界图像不同,丰富且不断演变的世界图像只是起点,而感觉信息被用于测试、探测和微调该图像。在接收新的感觉信号之前,预测性大脑已经在忙着描绘事物最可能呈现的样子了。
在此期间有一篇相当重要的论文:Friston, K., “A Theory of Cortical Responses,”Philo sophical Transactions of the Royal Society of London B Biological Sciences 29, 360(1456)(2005): 815–836。更早的相关作品,包括:Mumford, D., “On the Computational Archi tecture of the Neocortex II: The Role of Cortico-Cortical Loop,”Biological Cybernetics 66(1992): 241–251;以及Lee, T. S., and Mumford, D., “Hierarchical Bayesian Inference in the Visual Cortex,”Journal of Optical Society of America A, 20(7) (2003): 1434–1448。另请参见:Hinton, G. E., et al., “The Wake-Sleep Algorithm for Unsupervised Neural Networks,”Science 268 (1995): 1158–1160。
这大体上解释了所有下行连接的必要性。它们承载着来自大脑深处的预测,将预测推向感官外围。这也解释了仅用于维持大脑内在活动的巨大能耗,这些活动是为了维持即时预测的模型而必不可少的。当大脑接收新的感觉信息时,其任务就是确定该传入信号中是否有任何内容看起来像是重要的“新异信息”,即对我们尝试看到或做的任何事情都很重要,却又未被预测的感觉信息。越来越多的学者已开始相信,这正是我们的大脑处理感觉信息的主要方式。为了检验这一假设,过去10到15年间,计算神经科学和认知神经科学领域涌现了大量研究,现有理论已经能详细且可验证地解释这一过程,让我们得以理解温斯顿所说的“奇怪架构”了。 这些理论有各种称谓,包括“预测处理”“分层预测编码”“主动推理”。我将主要使用“预测处理”这个便捷的标签来概括它们。
需要注意的是,作为预测的根基,我们的许多知识都是终身学习的结果,但也有一些知识是演化的产物,它们已被自然选择预先安装为大脑的某些基本结构和连接模式了。参见:Teufel,C., and Fletcher, P. C., “Forms of Prediction in the Nervous System,”Nature Reviews Neuroscience 21(4) (2020): 231–242。此外,通过终身学习获得的一些知识可能会被压缩(通过一个被称为“平摊推理”的过程),形成快速、高效的连接,牺牲灵活性以换取速度。这些快速、冻结的连接可能(比如说)有助于我们快速领会特定场景的要旨,为主要的目标,也就是推动预测和预测误差信号更加复杂的相互作用铺平道路。有关平摊推理的更多信息,参见:Tschantz, A., et al., “Hybrid Predictive Coding: Inferring, Fast and Slow,”arXiv:2204:02169v2 (2022)。其在计划中的应用,参见:Fountas, Z., et al., “Deep Active Inference Agents Using Monte-Carlo Methods,”Advances in Neural Information Pro cessing Systems 33 (eds.) Larochelle, H., et al. (Red Hook, N.Y.: Curran Associates, 2020),pp. 11662–11675。
根据这种观点,感知的智能相机模型其实大谬不然。尽管它直观上很有吸引力,但对感知的正确解释(在大多数情况下)不应是一个主要从眼睛和其他感官向内运行的过程,大脑也永远不只是在那里耐心等待感觉信息的到来。 相反,它积极地预测感觉信息,运用它对世界中的图案和物体的所有了解——鸟儿的叽喳声(以及我爱人设定的晨起闹铃)、太过频繁的手机振动干扰以及我办公桌上各式物品的摆放。它还不断利用活动的身体,转动头部、眼球和肢体来获得新的、更好的信息。这样的大脑不是感觉信息的被动接收者和处理者,而是一个不知疲倦的预测者(而且我们稍后将看到,它还是一个熟练且主动的询问者),它基于自身的感觉信号流进行预测。
劣质收音机和受控的幻觉
参见:Hermann von Helmholtz, Handbuch der physiologischen optic, in J. P. C. Southall(ed.), (English trans.), Vol. 3 (New York: Dover, 1860/1962)。
当代对预测性大脑的描述源于19世纪德国物理学家、博学大师赫尔曼·冯·亥姆霍兹。亥姆霍兹发明了眼科医生用于检查眼睛的检眼镜,提出了能量守恒定律,还对知觉理论很着迷。他认为我们只有通过一种无意识的推理或推断才能感知世界,也就是大脑会问自己:“基于我所知的一切,世界必须是怎样的,才能让我接收当前呈现的信号模式?” 这是感知系统一开始就要解决的问题。
你可能还没意识到这在我们的日常生活中有多么普遍。如果你在收音机上听一首熟悉的歌,即使信号很差,歌词和节奏听起来仍然出奇清晰。但如果在相同的信号质量下听一首全新的歌,声音似乎更加模糊,人声也难以辨别。正如亥姆霍兹所言,在每种情况下,你的大脑都在利用它所知道的知识来推断是哪些词和声音最有可能引发你耳朵当前接收有些不完整的听觉信号。但是大脑对熟悉歌曲的猜测要好得多,也使它听起来更加清晰。事实上,这种猜测会改变大脑的反应,这种影响一直“向下”延伸到早期听觉处理区域,从而使这些反应更符合预期的声音。在非常现实的意义上,你的大脑现在正在为自己播放歌曲的大部分内容,利用自身存储的关于外部世界的知识修复糟糕的传入信号。
这是大脑在发挥其所长,根据其期望听到的声音填充和完善缺失的信号,从而产生“良性幻觉”。大脑了解歌曲的旋律,以及特定歌手演唱的各种微妙之处,它可以利用先验知识在歌曲播放时积极预测听觉信号最可能呈现的模式。如果没有接收来自外部世界的有力反证,这些预测就将塑造我们的听觉体验,让歌曲听上去更清晰。
需要强调的是,与其说这是记忆耍的把戏,不如说是我们了解感知本身运作方式的绝佳机遇。大脑对熟悉的歌曲的预测有助于它从噪声中提取信号,使声音比劣质收音机信号本身呈现给我们的更加清晰。这种感知方式高度活跃,涉及沿信号处理链路从高级处理区域向感官外围下行传递复杂的预测,以及每当检测到严重的不匹配时生成预测误差。这种反向的信息流有时被认知科学家称为“自上而下”的信息流。在这些过程进行的同时,人类感知者本身也是活跃的:我们会试图通过例如抬起头或转动眼珠等身体动作收集关键感觉信息。这些动作也是由预测机器选择和启动的,创建了心智与身体活动的一体化网络。随着故事的推进,我们将会更多地谈及行动的作用。
目前我们尚不清楚谁最早提出这个惊人的见解,但他很可能是机器学习领域的先驱马克斯·克洛斯。
一种对上述机制的生动描述是:它让预测占据了主导地位,使日常的感知变成了某种“受控的幻觉” ——大脑正在猜测世界是什么样的,利用感官证据来纠正和调整猜测。当内部猜测完全掌控一切时,我们只会产生幻觉,仅此而已。但如果猜测对感官刺激有适当敏感度——借助预测误差信号——猜测就是受控的,世界就能为心智所知。当我们从一台劣质收音机中听到熟悉的歌曲时,我们正受益于“良性幻觉”。尽管前言中提到的手机振动幻觉在那种情况下具有误导性,但它也是以同样的方式产生的。人类的一切体验都是以这种方式由预测处理过程构建的。我们通过预测世界来看见世界。但产生预测误差时,大脑就必须重新预测。
节俭的大脑
参见:Shannon, C., “A Mathematical Theory of Communication,”Bell System Technical Journal 27 (July, October, 1948): 379–423, 623–656。
用预测来解释感知还有一个重要的好处:它揭示了大脑如何以一种非常高效的方式处理传入的感觉信息。众所周知,信息科学的主要目标之一就是提高通信效率,这门科学在开发非常节俭的信号传输方式方面发挥了重要作用。20世纪中叶,全球电信系统由于需求持续增长而不堪重负。对电信巨头来说,要使用老式电话线传递越来越多的信息,就要直面通道噪声干扰严重且传输能力有限的问题。这给了信息科学以用武之地:信息理论家最终为提高信号传输的经济性而开发了一项沿用至今的强大技术——线性预测编码。
线性预测编码的起源可追溯至1948年香农发表的一篇论文,他是供职于贝尔实验室的数学家和密码学家。这篇重要的论文指出,英文文本可以利用单词和字母之间的可预测性,以一种非常高效的压缩方式进行编码。如果某个字母之后几乎总是跟着另一个字母,那么一个高效的编码方案就可以做这样的简单假设,除非遇见需要特别标记的例外情况。仅标记那些偶发的例外要高效得多——比编码每个字母更节约带宽。
有了恰当的预期,即便没有信号也能携带大量信息。假设你制订了一个计划,告诉别人,如果你不给他们打电话,那么一切都将“按计划进行”,也就是说,你会在当地时间下周三上午9点飞抵迈阿密,他们应该接机。直到那天,接机者都没接到电话,但这一事实(可转化为1比特的信号)恰恰传达了非常重要的信息:你将会乘坐飞机,在那个时间、那个地点抵达。其巧妙之处在于,接收者拥有的智慧与先见之明抵消了你本该为编码和传输所有信息而承担的成本。
无线电工程师协会的彼得·伊莱亚斯在两篇早期论文中提出了特别有先见之明的见解。这两篇发表于1955年的论文于1965年由曼弗雷德·施罗德和比什努·阿塔尔重新发现,他们同样在贝尔实验室工作。参见:Atal, B. S., “The History of Linear Prediction,”IEEE Signal Processing Magazine 161 (2006): 154–161。
各种基于预测的压缩技术已让电信技术的发展受益匪浅。 原则上,你可以利用关于特定信号最可能形态的先验知识来帮助预测接收端的信号,这样,珍贵的电线和电缆就可以只用来传输与预测模式不同的信号。接收端只要根据该残差对信号进行更新即可。这个过程的精妙之处在于,只需要传输少量的误差,就可以重构丰富的内容(比如图像或消息)。这些丰富的内容主要建立在预测的基础上,但能通过残差与现实锚定。
这种借助有依据的预测压缩信息的方法,其实就是通过“回补”(adding back in)所有能被成功预测的元素来有效地节约带宽。正因有了这门绝技,我们才能用JPEG和MP3等格式以经济的方式存储和传输图片、声音、视频文件。对图片文件而言,预测编码的原理是假设每个像素的值都可以根据相邻的各像素的值来实现较好的预测。在满足这种条件下(通常都满足),我们不需要传输该像素的值。所有需要编码的仅仅是预测值的偏差。但这只是一个简单的规律。只要存在任何形式的可检测的规律,预测(和借助预测的数据压缩)就可以实现。
参见:Musmann, H., “Predictive Image Coding,” in Image Transmission Techniques (Adv ances in Electronics and Electron Physics, Suppl 12), ed. W. K. Pratt (New York: Academ ic Press, 1979), 73–112。
我们再看看视频文件的运动压缩编码。1959年,视频文件的帧间预测编码技术问世。为了更好地理解,想象一下视频的内容是一个人在沿着走廊跑步。 视频的第4帧和第5帧的视觉背景没有任何区别,唯一的差异是跑步者前进了一点儿。有了现成的可预测内容(背景),我们只需要传输少量的差异(残差),就能完整地捕捉第5帧画面。换言之,你可以认为第5帧是对第4帧的微调,两帧画面的差异只在(比如说)脚的位置,因此将脚的位置信息通过系统传输的成本远远低于传输第5帧中每个像素的新值。这种技巧至今仍在使用。
现在请想象一个已经了解了更多信息的系统,比如,一个了解各种不同的奔跑步态的动态细节的系统。这样的系统能利用更详细(更“高层级”)的信息进行预测,因此只有意料之外的脚部动作才会引发预测误差信号。假设脚部动作和预期一致,那么就不需要更新帧间信息。这种更智能的系统甚至可以产生通常的持续运动幻觉,仅在有意外发生时更新(比如跑步者突然被绊了一跤)。无论预测有多复杂或高级,新异信息都要由预测误差来传递,在不符合预期之处发出信号,从而让我们与一个不断变化且时而令人惊讶的世界保持接触。
参见:Friston, K., “The Free Energy Principle: A Rough Guide to the Brain?,”Trends in Cognitive Sciences 13(7) (July 2009): 293–301。关于这套策略与人脑神经回路间关联的一些更详细的研究,参见:Bastos, A. M., et al., “Canonical Microcircuits for Predictive Coding,”Neuron 76(4) (November 2012): 695–711。对神经证据的状态有一个相当平衡的观点,参见:Walsh, K. S., et al., “Evaluating the Neurophysiological Evidence for Predictive Processing as a Model of Perception,”Annals of the New York Academy of Scienc es 1464(1): 2020: 242–268。另见:De Lange, F., Heilbron, M., and Kok, P., “How Do Expec tations Shape Perception?,”Trends in Cognitive Sciences, 22(9) (June 2018): 764–779。
人类大脑似乎受益于这种智能的预测策略,并使用了“多层信息处理”这一强大的方式。 在这种多层级的情境中,简单的预测被嵌套在不那么简单、更抽象的预测之中,就像我们在奔跑步态的例子中所示,对步态的预期是一种更高层级的预测,反过来又会生成关于实际脚部位置的预测(更低层级的预测)。在那一刻,预测误差形成并通过系统向上传输。这些细微的差异进而对各层级的猜测进行微调,比如跑步者当前的步态与我们的预期不符,因此要调整我们的预测,使其与信号更加契合。
在大脑的预测处理架构中,我们通常认为有不同的神经元集群专门负责不同的功能,因此较高的层级就能利用自己的专业知识和专属资源来尝试预测较低层级的状态。具体而言,一个专注于预测完整单词的层级可能会利用自己的知识来帮助预测更低层级的状态,后者专门识别字母。而负责预测单词的层级本身可能会被专门从事完整语句预测的更高层级预测。本书附录中提供了一个与此相关的详细示例以及其他细节。
目前需要注意的是,在这种多层级的安排中,所有向前流动(从感受器边缘流向大脑深处)的都是新异信息——与预期的偏差。这样非常高效。一些信息如果已得到了很好的预测,就不应占用宝贵的带宽来向上传递。如果你每天按部就班地工作,公司总部又干吗要费心思过问你的进度?同样,在神经层面,每个层级的预测误差只会传递预料之外的内容,即可能需要进一步思考或采取行动的内容。
像这样的系统在利用输入信息时非常节俭。相较于尝试从头处理每一条信息,它们会高效地筛选和过滤输入数据,只突出显示那些预料之外的部分。
说到底,人类对现实的体验是大脑产生的幻觉。这意味着我们所体验的世界在某种程度上是我们所预测的世界。感知绝不仅是一扇窥视世界的窗口,非要这样比喻,那就是镶在窗棂上的玻璃从一开始就带有我们自身的预测和期望的色彩:不仅意味着我们的观念和偏向会影响我们后续对事物的判断,预测还会在更深层、更原始的意义上塑造我们的感知过程——作为使我们与世界保持接触的特殊机制,感知活动始终在丰富的预测和期望的驱动下进行。
在接下来的章节中,我将尝试让你亲身体验预测的力量如何改变你的所见所闻。
预测的力量
图1—1提供了一个简单的示例。先从上往下,再从左向右看。请注意,每个序列的中间字符的形状都是相同的。但根据你看的顺序,视觉体验似乎会有微妙的不同。当从上往下看时,你的大脑开始预期那是一个数字(13),而从左向右看则引发了对一个字母(B)的预期。这些不同的预测会影响视觉体验本身。

图1—1 数字/字母网格
参见:Biderman, D., Shir, Y., and Mudrik, L. B., “Unconscious Top-Down Contextual Efects at the Categorical but Not the Lexical Level,”Psychological Science 31(6) (2020): 663–677。
研究表明,即使是数字/字母提供的无意识(“掩蔽”)呈现也会以某种方式让我们对居中的模棱两可的图形的感知产生偏向。掩蔽是一种技术,其中一个刺激物会先被短暂呈现,然后立即呈现一个不同的刺激物。这个过程阻止了我们对第一个短暂呈现的刺激物的意识觉知。尽管如此,被掩蔽的刺激物仍可以影响我们的行为和反应。在本例中,字母A和C的掩蔽呈现会让受试对象偏向于将居中的图形看成字母B,而数字12和14的掩蔽呈现则会让受试对象偏向于将居中的图形看成数字13。 这表明主动但无意识的预测也会让我们的反应和判断产生偏向。当我们稍后将本章所学应用于精神病学和精神医学中的更复杂示例时,这一点将变得很重要。
1英尺约为0.3米。——编者注
网上一些素材对此有很直观的演示,相关视频参见:www
. richardgregory.org/experiments/video/chaplin.htm。更多与“凹脸错觉”有关的讨论,参见:Gregory, R. L., “Knowledge in Perception and Illusion,”Philosophical Transactions of the Royal Society London, B 352(1997): 1121–1128。
接着,我们看一下“凹脸错觉”。你如果从背面去看一个面具(这种面具在搞笑玩具店里很常见),显然会看到它的凹面。但如果从另一面打光将面具照亮,而你离面具又有几英尺 远,就会看见一张正常的凸脸——它的鼻子和其他面部特征会明显地向外凸出。 这是因为我们习惯于从正面看人脸(我们确实很少看到它们的反面),于是大脑似乎会忽视表征凹陷的传入信号,并允许其根深蒂固的“凸面预测”占据主导。对名人或熟人的面孔(我们对其有最强烈和最详细的预测),凹脸错觉最为明显,如果将面具倒置,效果则会大大减弱或消失,这可能是因为这样做让我们能将其视为一个标准对象,而不是一个让我们有如此强烈且根深蒂固的凸面预期的对象。
视觉处理的最后一个例子,请看图1—2。

图1—2 穆尼图
穆尼图是以心理学家克雷格·穆尼的名字命名的,他在1957年手绘了许多这样的刺激物作为简单的工具来研究如何利用最少的信息产生有意义的视知觉。相关研究,参见:Mooney,C. M., “Age in the Development of Closure Ability in Children,”Canadian Journal of Psychology 11(4) (1957): 219–226。正文中的图片引用自Rubin, N., Nakayama, K., and Shapley, R., “The Role of Insight in Perceptual Learning: Evidence from Illusory Contour Perception,”Perceptual Learning, Fahle, M., and Poggio, T. (eds.) (Cambridge: MIT Press, 2002)。
对此我们可以多说两句。一旦你看过一幅穆尼图的原始图,而后再次看该穆尼图时,你就能利用更加丰富的知识库,该知识库将指导你如何对该图片进行视觉探索。至关重要的是,早期处理环节中检测与小狗有关的局部特征的神经元反应也会被锐化。尽管传入的感觉信息没有变化(仍是同一幅穆尼图),但更高层级的知识体系现在能很好地预测这些信息,早期特征检测器的响应方式也随之相应调整。更多关于如何预测解码穆尼图的信息,参见:Teufel, C.,Dakin, S. C., and Fletcher, P. C., “Prior Object-Knowledge Sharpens Properties of Early Visual Feature-Detectors,”Nature Scientific Reports 8, 10853 (2018)。
这幅所谓的穆尼图在你看来可能什么都不像,只是一些黑白的轮廓和斑点。 但现在看一眼原始的灰度图像(见图1—3),再回过头看穆尼图,你体验到的就会从根本上——而且可能是永远地——改变。穆尼图变得结构明确且有意义。你的行为也会受到影响,因为你的眼睛现在会以跟踪其显著特征的方式来检视穆尼图,视线尤其会落在小狗的眼睛和鼻子上。我们现在体验的是本书反复强调的核心效应之一。图片在第二次看时会有所不同,因为对世界的更充分了解(在这里是对原始图片的了解)让你的大脑能够做出更好的预测。

图1—3 图1—2所示穆尼图的全灰度版本
资料来源:Flickr, Boris Schubert。
正弦波语音和“绿针”效应
我们接下来的例子涉及声音,鉴于我们大概是用眼睛而不是耳朵来阅读,这些内容可能不那么直观。你如果现在不在一个可以联网的设备附近,仅仅阅读下面的文字就足够了。但你如果能够打开一些音频文件,就会发现非常值得:你将有机会亲身体验这些非常简单但又极富戏剧性的效应。
关于“正弦波语音”的原始论文,参见:Remez, R. E., et al., “Speech Perception Without Traditional Speech Cues,”Science 212 (1981): 947–950。如今人们对这一现象的见解和有关的音频实例,可见:马特·戴维斯的在线简介“An Introduction to Sine-Wave Speech”。
首先要讨论的现象被称为“正弦波语音”。正弦波语音录音是一种人为降低质量的正常语音录音,用纯音哨声代替了声音流的关键部分。这项技术是在20世纪70年代初由美国哈斯金斯实验室发明的,作为研究语音感知的本质 的一种手段,具体而言,就是对各种关于声音流的哪些部分对听语音至关重要的理论进行检验。正弦波语音听起来像是一系列起初难以理解的、包含升调和降调的哔哔声和哨声。
网上有许多录音(登录我萨塞克斯大学同事克里斯·达尔文的网页,可以找到一些我最喜欢的,或者只需搜索“正弦波语音”),它们听起来是这样的。首先,你会听到一段“语音”录音,质量低到听上去毫无意义可言。然后,你会听到原始录音,其中有人会说一个简单的句子,比如“水壶煮沸得很快”。之后,带有哔哔声和哨声的正弦波语音会再次播放。第二次听的时候,你的听觉体验会发生巨大改变。现在,你清楚地听到了语音中的词以及它们之间的间隔。这就像之前展示的穆尼图一样,只不过这次是以声音的形式。
如果你使用不同的例子多次练习,你就会迅速变得很熟练,甚至不需要先听原始的句子。听母语中的日常用语也有相同的技巧——你的预测越准确(也许是因为你认识说话者或者有相同的口音),声音听上去就越清晰。在每种情况下,都有一个良好的预测模型可以改善感知。这样的模型使用预测来帮助你从噪声中辨别信号。之前听起来像一系列无意义的哔哔声和哨声,现在听起来像是一个结构化的句子,尽管声音有点儿失真。与原始体验相比,差异是如此之大——就像将原始声音文件用另一个截然不同的文件替换了一样。
再举一例(有些人可能对这个例子已经很熟悉了),重复播放声音,同时从两个不同的词(或词组)中任选一个呈现在屏幕上,比如“brainstorm”(头脑风暴)和“green needle”(绿针)。令人惊奇的是,你听到什么似乎取决于眼前的是哪一个词,可这两个词听上去差异非常明显!这是因为眼前的词会使基于证据的平衡偏向于其中一种听觉预测而非另一种。你所体验到的显著差异再次揭示出你的听觉体验在多大程度上是由你自己的预测构建的。在搜索引擎中输入“green needle”和“brainstorm”,你将有机会亲身体验一番。
这些效应看似神奇,但它们都属于正常的感知现象。我们能借助感知理解自己所处的世界,既离不开外界传入的感觉信号,又要仰仗丰富的、基于知识的隐形预测。
“白色圣诞节”效应
请回想你非常熟悉的一首歌。现在问自己:如果这首歌的录音极其微弱,并且隐藏在一个大部分都是白噪声的三分钟声音文件中,我是否能察觉这首歌的一个片段?你可能不确定——你会认为这取决于它隐藏得有多好。早在2001年,荷兰马斯特里赫特大学的研究人员给一组本科生分配了这个任务,要求他们不论何时,只要自认为听到了这首歌就按下按钮。这首歌(宾·克罗斯比演唱的《白色圣诞节》)在他们进入实验室时正在播放,当时他们被要求确认这确实是一首熟悉的歌曲的曲调,然后他们被告知:
你刚刚听到的《白色圣诞节》歌曲可能隐藏在听觉阈限以下的白噪声中。如果你认为或者相信自己清楚地听到了这首歌,那么请按下你面前的按钮。当然,如果你认为自己听到了这首歌的多个片段,你可以多次按下按钮。
歌曲的选择反映了研究的最早起源,该研究可追溯至1964年,当时宾·克罗斯比仍然是世界上最著名的歌手之一。最初的论文是:Barber, T. X., and Calverey, D. S., “An Experimental Study of Hypnotic (Auditory and Visual) Hallucinations,”Journal of Abnormal and Social Psychology 68 (1964): 13–20。文中将这种现象描述为“催眠幻觉”。针对本科生的实验研究,参见:Merkelbach, H., and van de Ven, V., “Another White Christmas: Fantasy Proneness and Reports of ‘Hallucinatory Experiences’ in Undergraduate Controls,”Journal of Behavior Therapy and Experimental Psychiatry 32 (2001): 137–144。更大规模的后续实验,参见:van de Ven, V., and Merkelbach, H., “The Role of Schizotypy, Mental Imagery, and Fantasy Proneness in Hallucinatory Reports of Undergraduate Students,”Personality and Individual Diferences 35 (2003): 889–896。
录音被播放后,学生们在觉得自己听到了隐藏的曲调时按下了按钮。每个试次后,他们还被要求报告自信水平。如果他们百分百确定自己在某个时刻听到了这首歌,他们会给自信水平打100分,以此类推,一直到0分,这意味着他们确信自己根本没有听到。其实,这个实验的巧妙之处在于录音中根本没有任何所谓隐藏歌曲的痕迹——录音中全是白噪声,没有一点儿《白色圣诞节》的曲调。但在这项研究中,约有1/3的学生至少按了一次按钮——一个值得注意的结果。几年后,这个实验成功地被一组更大规模的学生复制。 时至今日,类似的实验已有很多,它们都使用了《白色圣诞节》这首老歌。通过操纵人们的期望(让受试者期望听到歌曲的微弱片段),研究者可靠地诱发了受试者对宾·克罗斯比的轻声吟唱的“幻听”。
压力和咖啡因摄入增强“白色圣诞节”幻觉的倾向,参见:Crowe, S. F., et al., “The Efect of Cafeine and Stress on Auditory Hallucinations in a Non-Clinical Sample,”Personality and Individual Diferences 50 (2011): 626–630。精神分裂症的影响,参见:Mintz, S.,and Alpert, M., “Imagery Vividness, Reality Testing and Schizophrenic Hallucinations,”Journal of Abnormal Psychology 79 (1972): 310–316,以及Young, H. F., et al., “The Role of Brief Instructions and Suggestibility in the Elicitation of Auditory and Visual Hallucina tions in Normal and Psychiatric Subjects,” Journal of Nervous and Mental Disease 175(1987): 41–48。
在这种情况下,听到《白色圣诞节》的调子并不意味着精神疾病或异常,而是反映了我们的大脑构建日常体验的方式。事实上,这为研究预测性大脑提供了一条明显的线索:典型和非典型的人类体验是以非常相似的方式构建的。这是“计算精神病学”这一颇有前景的新领域的核心洞见,详见第2章。
被用于解释“白色圣诞节”效应的理论不止一种。例如,在2001年的研究论文中,研究者注意到那些最明显表现出这种效应的人在“幻想倾向”心理测试中的得分通常也要更高。2011年的另一项研究发现,这种效应(就像手机振动幻觉一样)会因压力和咖啡因的摄入而显著增强。还有一些证据表明,精神分裂症患者虚报歌曲的次数和对此的信心水平都更高,我们稍后再讨论这一领域的研究。 似乎不容置疑的是,实验诱发的对听到歌曲的期望在构建幻觉体验方面发挥了主导作用,就像我自己对听到鸟鸣闹铃的预测一样。
那条裙子和其他幻觉
2015年2月,一丝源自社交媒体的火花引起了一场不可阻挡的、火遍互联网的热议,引发了1000万次快速转发,并且活跃了许多家庭的晚餐聊天。这丝火花其实是一张照片,拍的是一条要用于参加苏格兰婚礼的裙子。许多读到这段文字的人都能想起这件事,并认为那条裙子明显是白金相间的,而另一些人则坚信它是蓝黑相间的。你如果当年信息闭塞,现在可以上网查看一下。我当时坚定地站白金色阵营,但我们输了(如果这事儿有胜负一说),因为在正常光线下观看时,那条裙子确实是蓝黑相间的。我们该如何理解这种体验之间的根本差异呢?
图1—4展示了所谓的蓬佐错觉的一个版本。这两个侧脸剪影的尺寸完全相同(去量一下它们的尺寸吧),但在现实世界中,最好的解释(考虑到视角)是远处的头更像是一个巨人的脑袋。这表明,正如亥姆霍兹所认为的那样,我们所看到的并不是事物原本的样子:更准确地说,我们将自己大脑的推断(猜测)视为感官证据传入的最可能的诱因。

图1—4 蓬佐错觉的一个版本
注:图片中的两个剪影尺寸完全相同。
资料来源:eyeTricks 3D Stereograms / Shutterstock。
参见:Witzel, C., Racey, C., and O’Regan, J., “Perceived Colors of the Color-Switching Dress Depend on Implicit Assumptions About the Illumination,”Journal of Vision 16(12)(2016): 223。
基本相同的推理也适用于裙子案例。但在裙子案例中,不同的看法之所以产生,是因为不同人的大脑似乎对所描绘的场景有相当不同的假设,尤其是两个阵营(蓝黑色和白金色)对室内的照明条件有不同的假设。这些假设包括室内亮度的一般水平、光源的位置,以及裙子是否在阴影中。对这些条件有不同假设的大脑会对裙子的颜色做出不同的推断,让一些人明确无疑地视裙子为蓝黑色,另一些人则同样明确无疑地视其为白金色。
为了证实这一理论,纽约大学的帕斯卡尔·瓦利施和他的团队对1.3万名受访者进行了在线调查。受访者不仅被问及在他们看来照片中的裙子是什么颜色的,还被问及他们认为照片拍摄时的光照条件如何,即他们认为照片是在人造光源还是在自然光下拍摄的(或是不确定)。果然,结果显示了两者的高度相关性,即那些认为是自然光的人更倾向于将裙子看成白金相间,而那些认为是人造光源的人更倾向于将裙子看成蓝黑相间,那些不确定的人则两种回答都有。
关于晨型人与夜型人的研究,参见:Wallisch, P., “Illumination Assumptions Account for Individual Diferences in the Perceptual Interpretation of a Profoundly Ambiguous Stimulus in the Color Domain: ‘The Dress,’” Journal of Vision 17(4) (2017): 1–14。
为什么身处同一世界的不同个体会做出如此不同的假设呢?这里有一个有趣的转折。受访者还被问及自认为是晨型人还是夜型人。晨型人是那些倾向于早睡早起并在早晨感觉最好的人,而夜型人则恰好相反,更喜欢晚睡晚起并在夜晚感觉最好。令人惊奇的是,这些自我认定的“昼夜节律类型”与对那件裙子的色彩感知存在着明显的关联。晨型人倾向于认为裙子是白金相间的,夜型人则倾向于蓝黑相间。报告这项研究结果的作者推测,受访者的日常生活习惯为他们更多地提供了其中一种而非另一种类型的体验(自然光相对人造光源),因而他们看待照片的方式有所不同,会根据他们自己与世界的感知互动的经历做出对光照的假设。
在某种意义上,这并不令人惊讶。大脑对光源性质和来源的预测必须有一定的基础,而个人经历在这方面必定起着重要作用。从另一种意义上说,让人感到惊讶的是,我们对一张简单照片的看法竟如此不同,这些不同植根于——事实上,相当微妙地响应于——我们独特的日常习惯。这是我们第一次在讨论中碰到具有重要影响的话题:我们自己的日常行为如何影响我们大脑的预测模型。我们个人的行为和经历塑造了大脑中的预测机制,这一机制反过来塑造了我们作为人类的意识,直至影响对我们来说属于基本感官体验的层面,比如我明确无疑地看出那条裙子是白金相间的。
学会预测
预测有助于构建我们所有的体验,因此自然而然地引出了一个问题:那些预测最初从何而来?诚然,我们先具备感知和体验这个世界的能力,才能学会做出预测,对吗?但问题是,如果我们的感知依赖于一个已经存在的良好的预测模型,我们又该如何习得一个良好的预测模型?
在某种程度上,我们显然不是从零开始的。数百万年的进化决定了我们出生时已经具备的基本配置:大脑的早期神经连接、感觉器官的结构,以及身体的形状。多亏了这一切,我们在启程时就已经拥有了大量来之不易的知识。你甚至可以说(可能有点儿牵强)拥有肺的生物在结构上已经“预期会呼吸”。但是,进化还留下了很多待做的,而像我们这样的生物就专门在反复的感官接触的基础上学习认识世界。
在这方面,预测机器开始扮演另一个极其互补的角色,因为事实证明,我们可以通过尝试预测我们自身的感觉信号流来驱动学习。这意味着,仅仅通过试图预测世界,我们就能获得后来使我们能够更好地预测世界的知识。这听起来有点儿像魔法,仿佛凭空变出一个良好的预测模型。虽然其中并没有魔法,但这个巧妙的过程仍然令人印象深刻!通过尝试(和可能失败地)预测世界,我们可以学会做得更好,直到我们的预测成功。
在思考这一过程时,重要的是区分原始的感官证据(比如光线和声音的传入模式)与我们由此形成的有意义的感知体验。如果没有足够好的预测模型,我们就无法成功地将这些原始的证据转化为对这个世界近似连贯的理解。这就像看那些穆尼图一样,或者更糟糕。即便如此,大脑仍然可以设法学习。它通过不断寻找更好的方式来预测难以驾驭的传入信号来做到这一点。婴儿似乎将大部分时间花在做这件事上,试图从感觉信号流中提炼有用的模式。
我们已经充分了解的机器学习技术清楚地表明了这如何成为可能。通过反复尝试预测感官证据流,某些类型的系统可以逐渐提高它们最初糟糕的预测性能,直到构建一个有用的预测模型。这样的系统在起始阶段甚至可以只使用一个随机生成的“模型”,毫无疑问,其预测性能确实会非常糟糕。但只要这一人工神经网络无法生成良好的预测,它就会改变自身信息处理业务的例程,使其在下一次预测时有可能表现得更好。随着时间的推移,这样的过程会挖掘出做出良好预测的方法。由此可知,要习得一个良好的预测模型,可以从一个非常糟糕(或完全随机)的模型开始,通过逐步改进慢慢实现。
在视觉领域,计算神经科学家拉杰什·拉奥和达纳·巴拉德在20世纪的最后几年创建的一个人工神经网络有力地证明了预测驱动学习的效力。他们用大量从自然场景图片中提取的样本(包括斑马、天鹅、猴子和森林的图片)训练该网络。样本图被输入一个简单的预测架构,其中各层级都致力于预测下一层级的当前活动。随着时间的推移,最初一无所知的网络开始习得自然场景图片中的模式,这证明预测的努力有助于习得成功的预测所需的知识。参见:Rao, R., and Ballard, D., “Predictive Coding in the Visual Cortex: A Functional Inter pretation of Some Extra-Classical Receptive-Field Effects,”Nature Neuroscience 2(1)(1999): 79。
通过尝试预测来学习预测的一大好处在于世界本身会不断纠正你的错误。如果我错误地预测了你即将说出的下一个词,接下来我的耳朵接收的就是对应正确词的声音流。我的大脑可以利用这一信息尝试改善下一次预测。这很好理解。例如,学习预测句子中最可能出现的下一个词的一种有效方法是暗中掌握足够的语法知识。但学习语法的一种好方法是一次又一次地尝试预测你将要听到的下一个词。只有在不断的尝试中,你的大脑才有可能逐渐无意识地发现那些能让你进行更好预测的规律。
感知即预测
那么,当你身处现实世界中,远离穆尼图和正弦波语音,你的预测性大脑会如何运作呢?假设你正在森林中露营,四周都是宁静、平和的自然景观。你已经在帐篷里窝了一整夜,第二天一大早,当你走出帐篷时,你的朋友们已经醒来并很快引起了你的注意。他们指着你脑袋上方说:“看看那边的树。”当你的眼睛看向朋友所指的方向时,你的大脑会采取哪些步骤呢?请记住,我们的大脑从来不是从零开始的——即使当你早晨第一次在一家新旅店或度假地醒来时,你的大脑也已经在忙碌地预测着什么了。随着你抬头仰望,新的感觉信息波抵达了。有反射光“撞”到了你的视网膜上,可能还有声音传入了你的耳朵,气味进入了你的鼻孔,以及各种触觉刺激你的皮肤。另外(我们将在后文详细探讨这一点),还有来自你的肠道、心脏和其他器官的内部信号。
简单起见,我们只考虑反射光,它刺激了你视网膜上的细胞,然后它们向大脑发送信号。当这些信号到达早期视觉处理区域时,它们会被你的大脑用来与当前预期的信号进行比较。也许你的大脑只期望一些相当普通的树木,尤其是你如果像我一样并非护林人。或者它在预测某种更具体的树。也许你知道自己在森林中某个特定的地方,你的大脑正在预测特定树的视觉信息。
不论以哪种方式,你都没有预测到你现在看到的正栖息在树梢上的知更鸟。你的大脑的最佳预测与感官证据相遇,会产生至关重要的残差。这些预测误差信号编码了你的大脑到目前为止还无法预测的感觉信息,向上(和横向)流动到大脑更深的区域,用于生成新的、改进的猜测。这些误差信号会作用于相应的结构,看有无已知信息可用于生成更成功的预测,能更好地匹配实际的感觉信号的预测。而后,大脑做出了更好的下行预测,包含更丰富的细节,比如周遭树木和树梢上那只知更鸟的外观。
知更鸟可能会让你大吃一惊——也许它们通常不在每年的这个时候出现。但是预测和预测误差的交换速度非常快,所以我们无法意识到表面之下所有正在进行的疯狂活动。对你而言,事情很简单:你看向朋友所指的地方,看到了那棵树,上面落了只知更鸟(这有点儿令人惊讶)。你当然不会先看到一个粗略的树轮廓,再看到一个更细致的树轮廓,这次包括一只鸟。一切发生得太快,但在某种意义上,这正是大脑内部真实的运作过程。
图1—5有效阐释了这一过程。其中,上方图片描绘了大脑如何处理信息的传统视角。左侧部分代表我们的视网膜接收的原始感觉数据,右侧覆盖在上层的卡通图案则代表我们从这些数据中提取有关外界信息的过程。但根据下方图片(预测处理视角),我们并不是从原始数据出发,而是从一个预测开始的,在这个例子中,是一棵相当普通的树。当传入的感觉数据与这个预测进行比较时,很快就会发现这里有一些意外情况,远远超出了对普通树的预测所能解释的范围。预测误差信号就产生了,启动了一段反复的过程,使被修正的预测与感官证据相匹配。经过一连串此类交换后,大脑最终形成对场景的稳定解释,这个解释现在包括了意想不到的知更鸟,并且(尽管图中未予展示)补充了关于树的更多细节。
请注意,千万别以为我们能体验到我所说的“感官证据”或“原始感觉信号”。相反,我们只有在感官证据(如撞到视网膜上的反射光的模式)与越来越准确的对该证据的预测相匹配时,才能“体验到”一些东西,而我们的预测是从过往经验和学习中提炼出来的。最初的预测就像粗略体验的草稿:我们辛苦获得的关于世界的基本知识通常让我们能做出很好的初步尝试,但体验是通过对这些草稿(基于由此产生的预测误差)的迅速改写来构建的。换言之,体验反映了随着未被预测到的感觉信息(预测误差)在系统中流动,我们调整最初的预测的方式。这些预测误差标记出意外信息,并要求进行新的、更好的预测。图1—6描绘了这一流程。更为详细的相关阐述可以参阅附录。

这些论述源于柯蒂斯·凯利的一篇关于预测处理理论的通俗介绍。凯利在日本语言教学协会(JALT)的心智、大脑和教育特别兴趣小组工作。图片摘自预测处理的入门读物,Bwlletin of the JACT Mind, Brain, and Education SIG 6(10), (October 1, 2020)。
▲图1—5 如传统视角(上方图片)所示,感觉信息被收集后沿着信息链传递,在此过程中与记忆相匹配,并激活更抽象的理解。如预测处理视角(下方图片)所示,你从一个主动模型(大脑对可能存在之事的最佳猜测)开始,然后使用由此产生的预测误差(这里由表征知更鸟的意外视觉信息引起)来完善和修正这种猜测
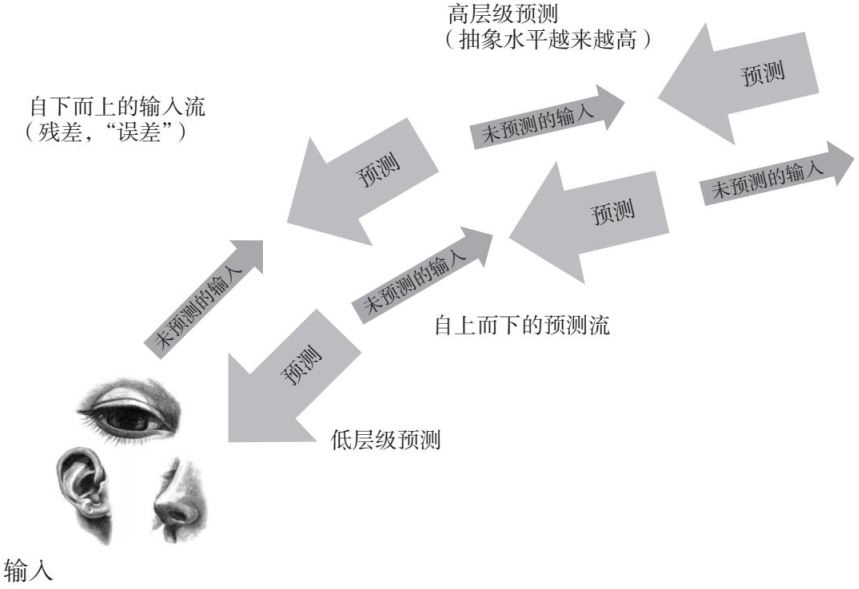
▲图1—6 预测处理视角下对大脑中信息流动的高度图化。感觉输入是在来自大脑深处的预测(基于先验知识和过往经验)的背景下进行处理的。预测误差标记出感觉信号中未被预测到的部分。这些误差会前馈流动,触发经过修正的预测
关于该主题的另外两本著作分别为:Jacob Hohwy,The Predictive Mind (New York
: Oxford University Press, 2013),和我自己的作品Surfing Uncertainty: Prediction, Action, and the Embodied Mind (New York: Oxford University Press, 2016)。Anil Seth,Being You: A Science of Consciousness (Penguin, UK, 2021)提供了认知神经科学的见解。Lisa Feldman-Barrett,How Emotions Are Made: The Secret Life of the Brain (New York: Houghton Miflin Harcourt, 2018),探讨了身体预测的强大作用。
从虚幻的手机振动到对鸟鸣声和《白色圣诞节》的幻听,再到在林中看到一只真实的知更鸟,我们的体验深受大脑持续预测的影响。大脑是预测机器,我们体验外部世界甚至自身的方式反映了这一简单却具有变革性的事实。 这改变了我们对心智、感官证据、身体感受、医学症状乃至与现实本身的关系的看法。